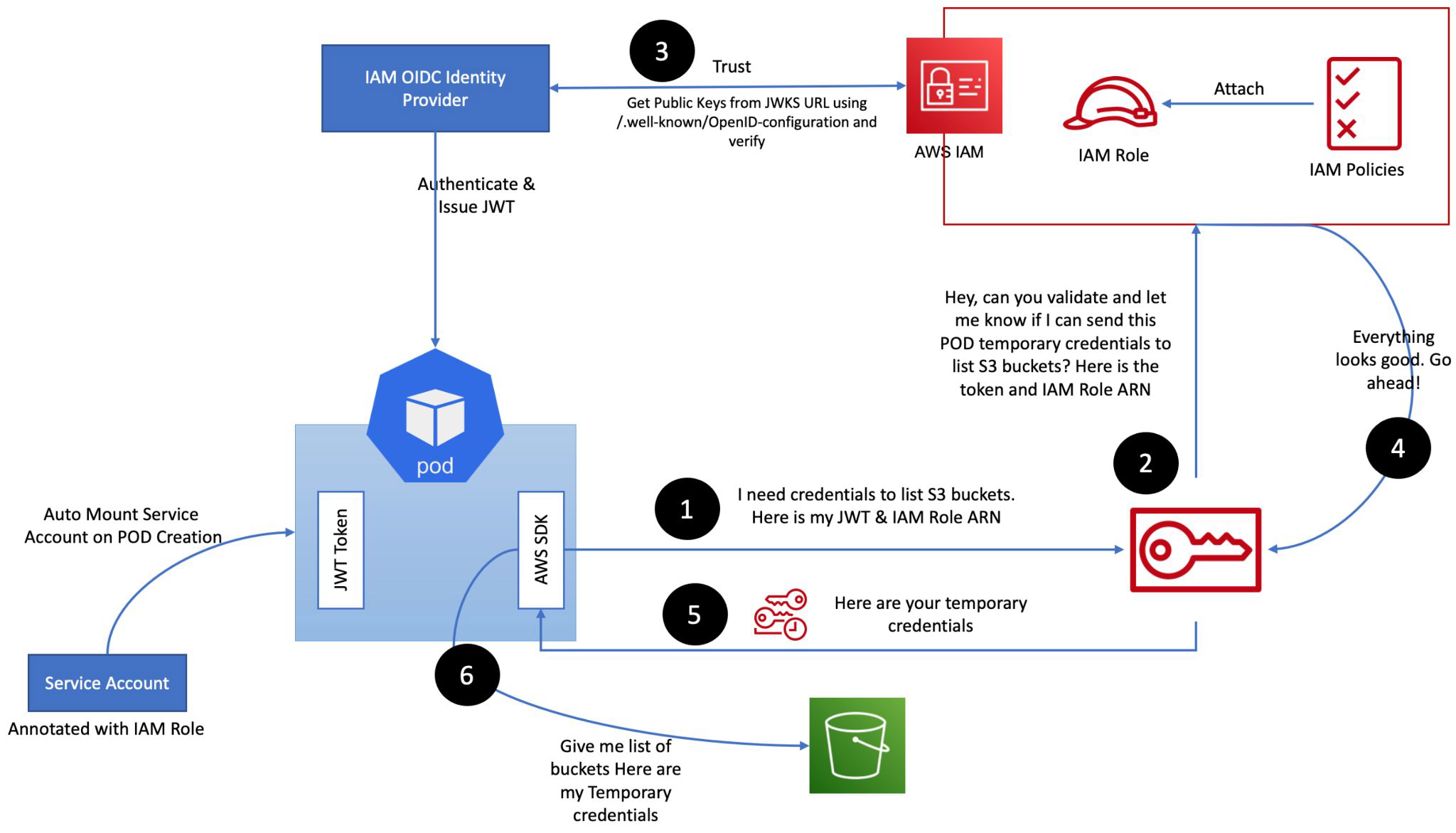
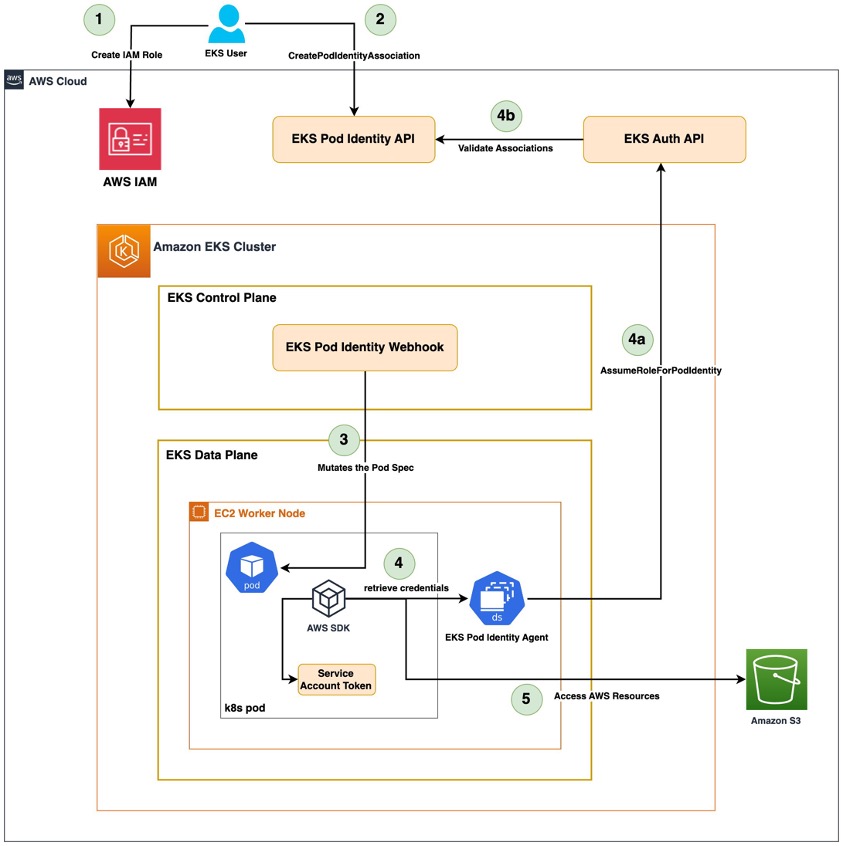
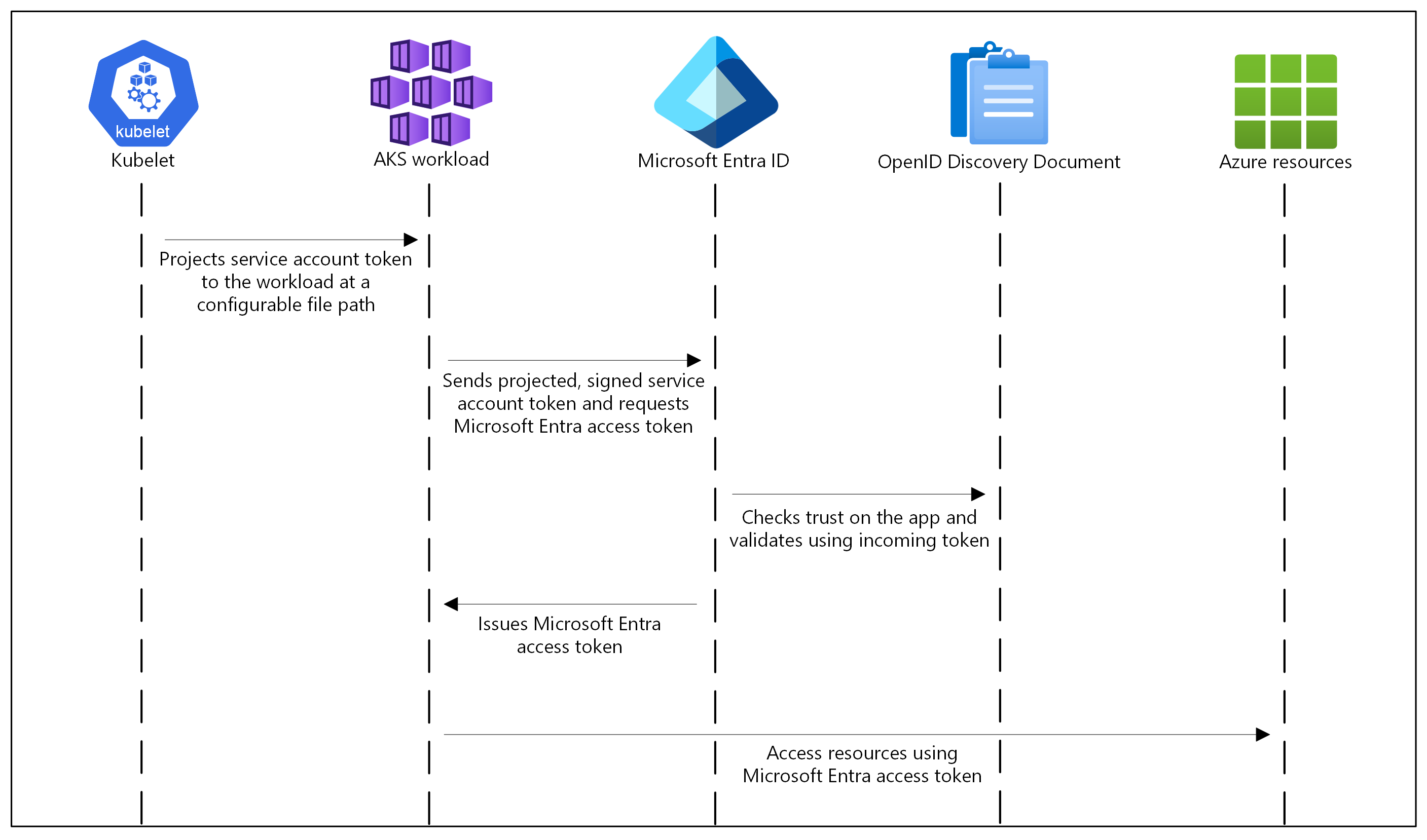
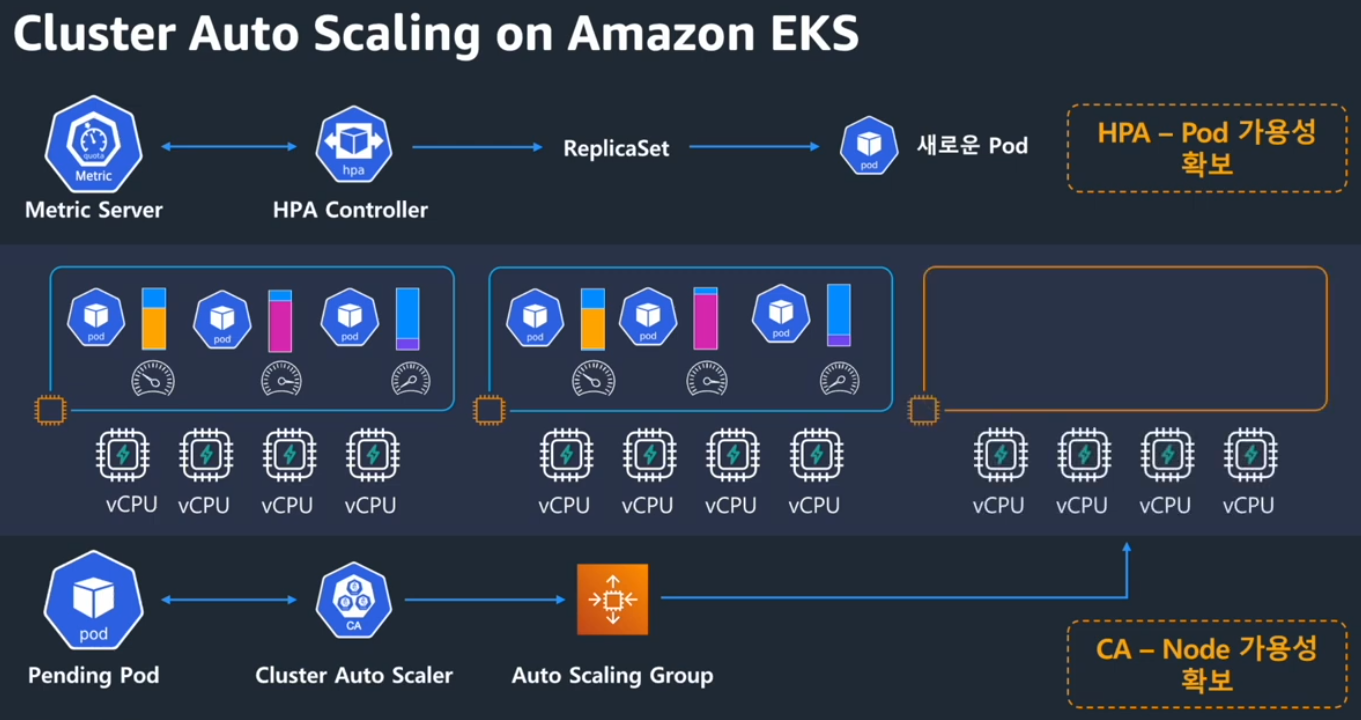
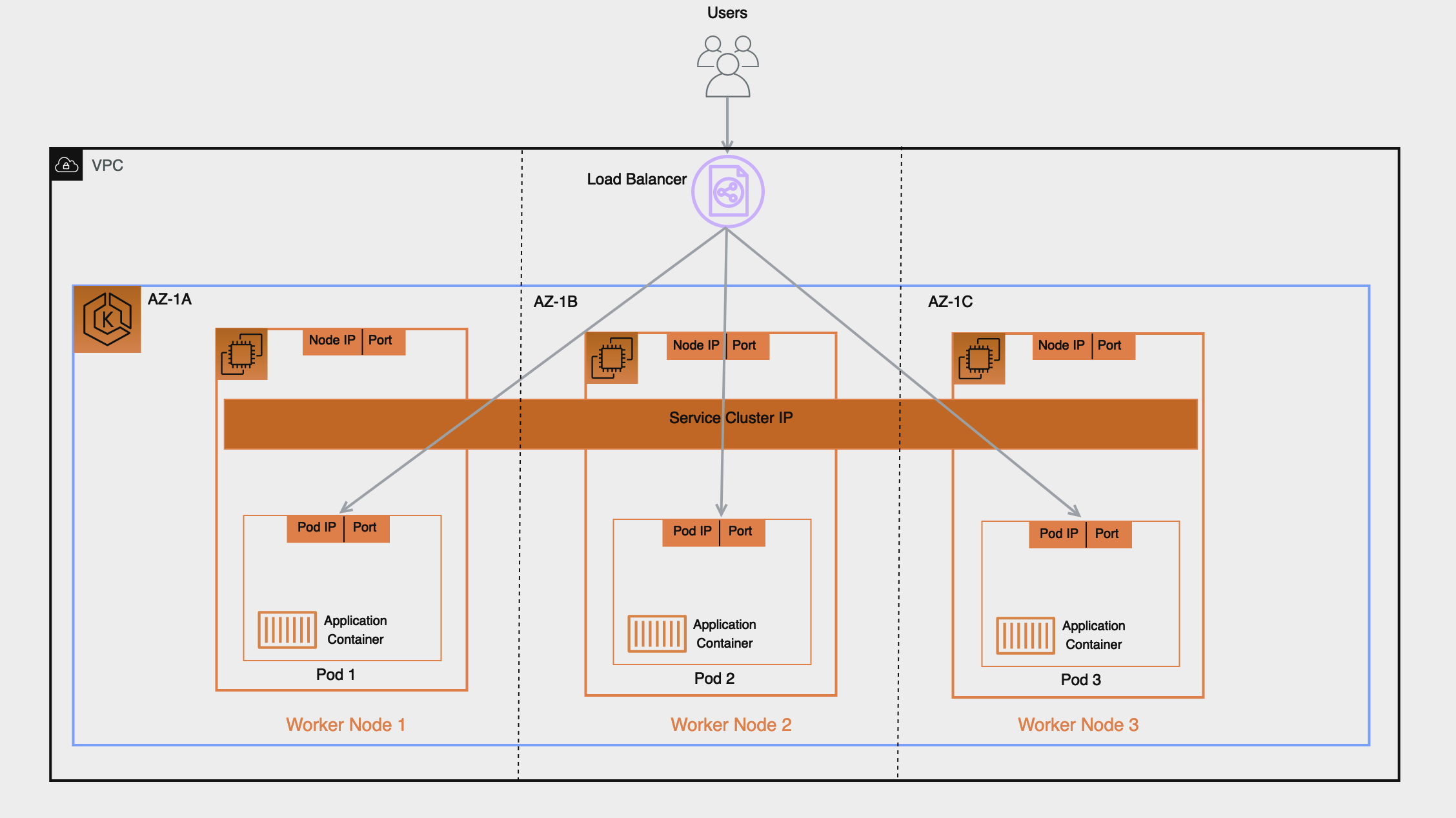
이번 포스트에서는 EKS Upgrade를 실습을 통해서 알아보겠습니다.
본 실습은 EKS Workshop인 Amazon EKS Upgrades: Strategies and Best Practices 를 바탕으로 진행하였음을 알려드립니다.
해당 워크샵 링크는 아래와 같습니다.
https://catalog.us-east-1.prod.workshops.aws/workshops/693bdee4-bc31-41d5-841f-54e3e54f8f4a/en-US
목차
- EKS의 업그레이드와 전략
- 실습 환경 개요
- In-place 클러스터 업그레이드
3.1. 컨트롤 플레인 업그레이드
3.2. Addons 업그레이드
3.3. 관리형 노드 그룹 업그레이드
3.4. Karpenter 노드 업그레이드
3.5. Self-managed 노드 업그레이드
3.6. Fargate 노드 업그레이드 - Blue/Green 클러스터 업그레이드
1. EKS의 업그레이드와 전략
쿠버네티스의 버전은 semantic versioning을 따르며, 특정 버전을 x.y.z라고 할 때 각 major.minor.patch 버전을 의미합니다.
새로운 쿠버네티스 마이너 버전은 약 4개월 바다 릴리즈 되며, 모든 버전은 12개월 동안 표준 지원을 제공되고, 한시점에 3개의 마이너 버전에 대한 표준 지원을 제공합니다. 표준 지원을 제공한다는 의미는 해당 버전에 대해서 패치가 지원된다는 의미로 이해하실 수 있습니다.
Amazon EKS는 쿠버네티스의 릴리즈 사이클을 따릅니다만, 세부적으로는 조금 더 넓은 범위의 지원을 보장합니다. EKS에서 특정 버전이 릴리즈되면 14개월 간 표준 지원이 되며, 또한 총 4개의 마이너 버전에 대한 표준 지원을 제공합니다.
현재 지원하는 쿠버네티스 버전에 대해서 아래 Amazon EKS kubernetes 릴리즈 일정을 살펴보시기 바랍니다.

EKS는 표준 지원(Standard Support)이 지난 이후에도 12개월의 확장 지원(Extended Support)을 제공하지만 이는 비용이 추가 됩니다.
웹 콘솔에서 EKS 클러스터의 Overview>Kubernetes version settings>Manage를 통해 Upgrade policy를 선택할 수 있습니다.
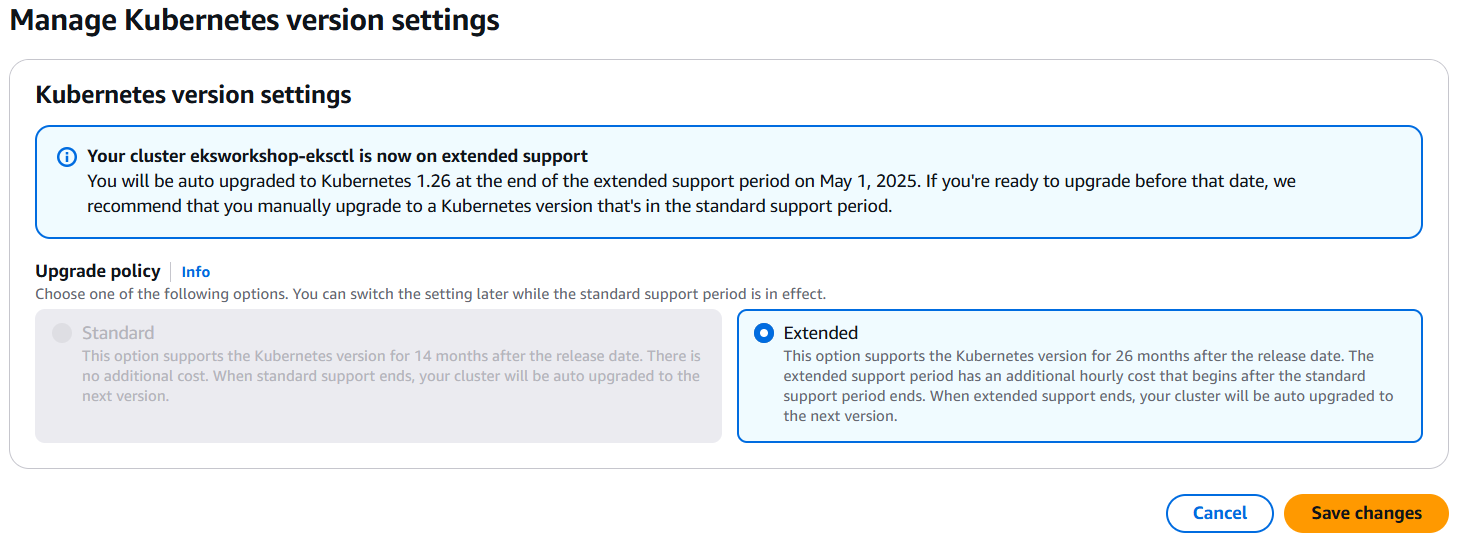
이때 표준 지원을 선택하는 경우, 표준 지원 기간이 종료되면 자동 업그레이드 되는 점을 유의하셔야 합니다.
버전 업그레이드에 대해서 고민해야 될 부분은 특정 버전이 14개월 동안 표준 지원되기 때문에 14개월 뒤에 업그레이드를 한다고 생각하실 수도 있지만, 사실 1개 버전만 업그레이드 하는 경우, 다음 버전의 EOS가 곧 도래하기 때문에 몇단계를 더 업그레이드 해야만 다시 1년가량을 안정적으로 사용하실 수 있습니다.
예를 들어, 1.27 버전이 2023/05/24~2024/07/24 까지 표준 지원 기간이지만, 2024년 7월에 1.28로 업그레이드를 해도 2024/12/26일에 다시 EOS가 도래합니다. 그렇기 때문에 실제로는 1.27->1.28->1.29->1.30까지 업그레이드를 해야 이후 1년 정도 EOS 이슈가 없이 사용할 수 있습니다.
EKS 업그레이드 과정
EKS의 업그레이드 과정은 실제 업그레이드에 대한 검토와 백업과 같은 내용을 제외하고 클러스터 자체를 업그레이드 하는 작업에 대해서만 설명합니다.
전반적인 업그레이드 절차는 아래와 같이 이뤄집니다.
1) 컨트롤 플레인 업그레이드
2) Add-on 업그레이드
3) 데이터 플레인 업그레이드
이때, 데이터 플레인의 형태가 다양한 경우, 세부적으로 데이터 플레인의 업그레이드 방식이 달라질 수 있습니다.
EKS 업그레이드 전략
EKS의 업그레이드 전략은 In-place 업그레이드와 Blue/Green 업그레이드가 있습니다.
In-place 업그레이드는 현재 운영 중인 클러스터에서 버전을 업그레이드 하는 것을 의미하며, Blue/Green 업그레이드는 신규 클러스터(Green)를 생성해 워크로드를 생성한 뒤 신규 클러스터로 전환하는 방법을 의미합니다.
업그레이드에 대한 세부적인 정보를 아래와 같은 문서를 참고하시기 바랍니다.
- Best Practices for Cluster Upgrades
https://docs.aws.amazon.com/eks/latest/best-practices/cluster-upgrades.html
- Kubernetes cluster upgrade: the blue-green deployment strategy
또한 중요한 사항은 Kubernetes Version Skew 정책입니다.
https://kubernetes.io/releases/version-skew-policy/#supported-version-skew
Kubernetes version skew 정책의 의미는 주요 컴포넌트(ex. kube-apiserver, kubelet, etc) 간 버전 차이가 얼마나 허용되는지에 대한 규칙입니다. In-place 업그레이드에서 여러 버전을 순차적으로 업그레이드할 수 있는데, 컨트롤 플레인과 데이터 플레인 간 허용되는 버전 내에서 업그레이드를 고려해야 합니다.
예를 들어, kube-apiserver의 버전이 1.32일 때, 허용되는 kubelet, kube-proxy의 version skew는 1.29까지입니다. 그러하므로 1.29에서 컨트롤 플레인 버전을 1.32까지 업그레이드 할 수 있고, 이후 노드 그룹의 버전을 순차적으로 업그레이드 하시면 됩니다.
또한 Kubernetes 의 In-place 업그레이드는 단계적인 버전 업그레이드만 지원되는 점도 유의를 해야 합니다. 한번에 여러 버전을 업그레이드 할 수 없습니다.
업그레이드 전 사전 검토 과정에서는 Cluster Insight 의 Upgrade insight를 검토해보기 바랍니다.
여기서는 아래와 같이 Kubernetes version skew, 클러스터 상태, add-on 버전 호환성, Deprecated API 에 대한 검토가 이뤄지는 것을 알 수 있씁니다.
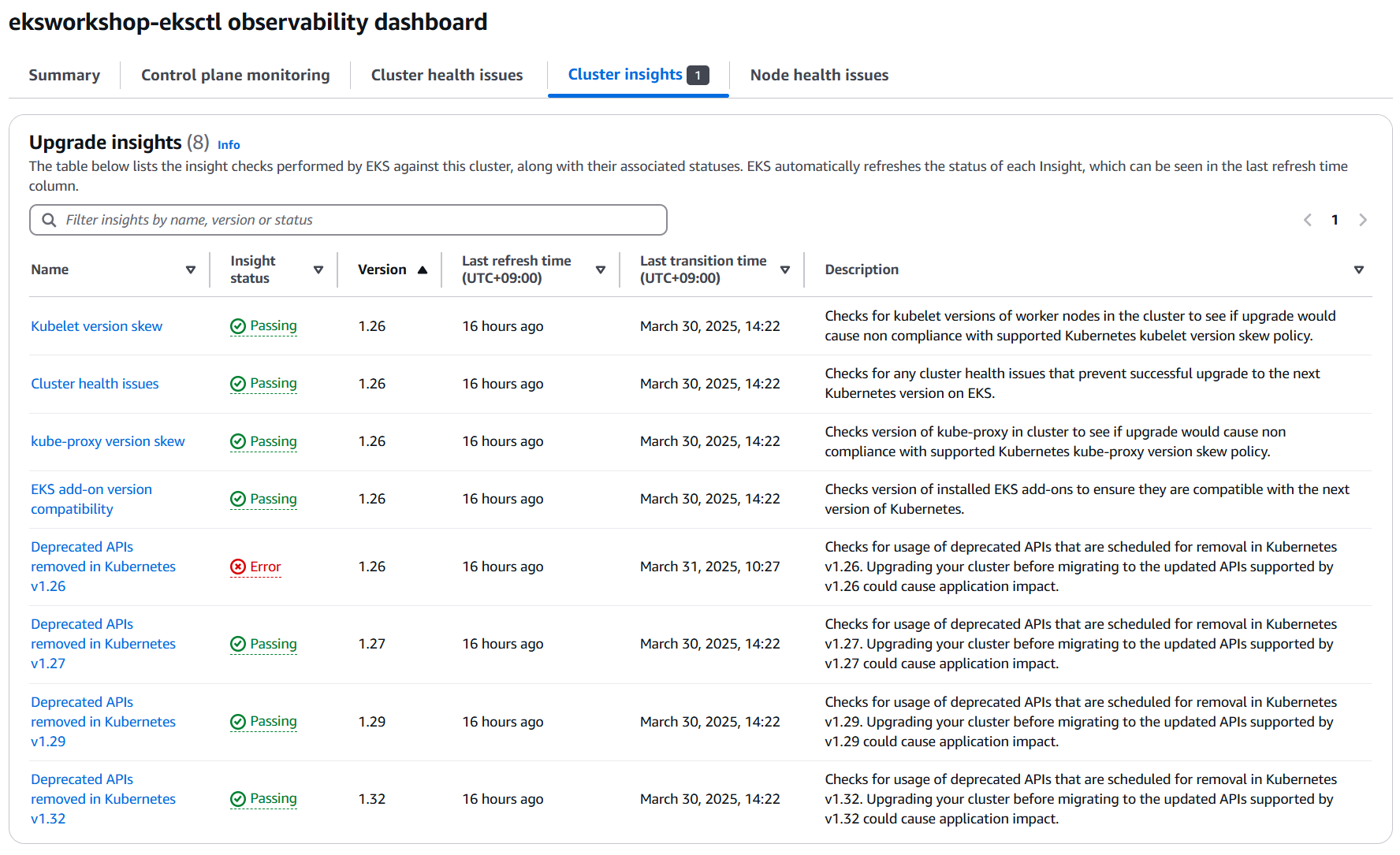
이후 실습을 통해서 상세한 내용을 살펴보겠습니다.
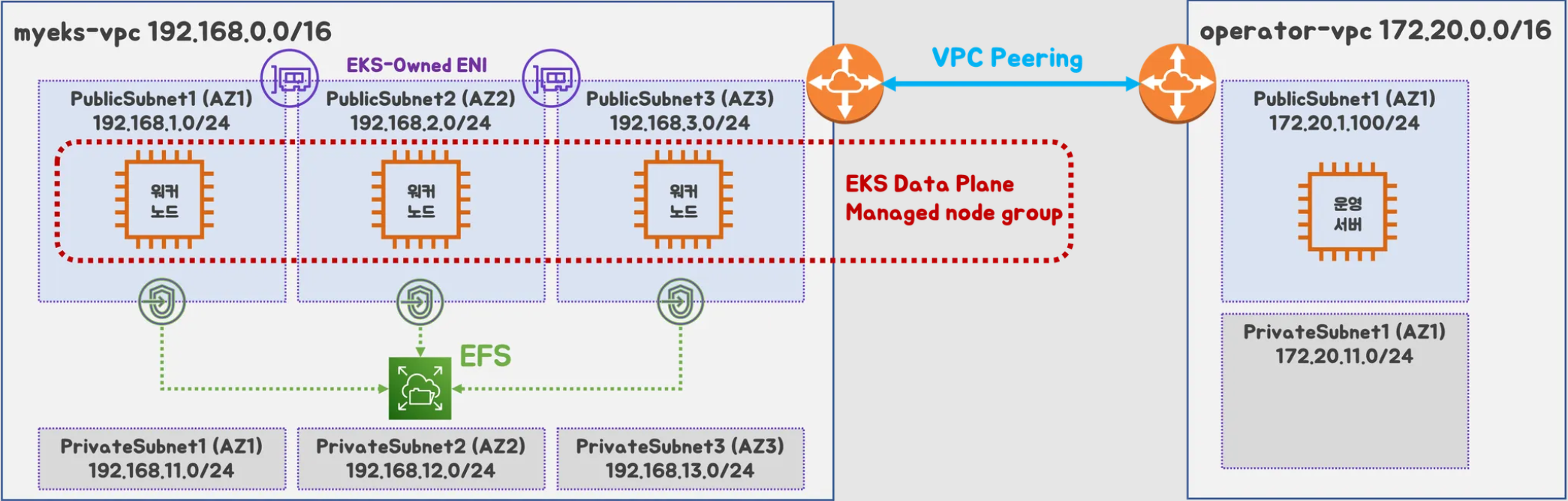
2. 실습 환경 개요
본 실습에서는 EKS 1.25 클러스터이며 Extended upgrade policy에 해당하는 것을 알 수 있습니다.

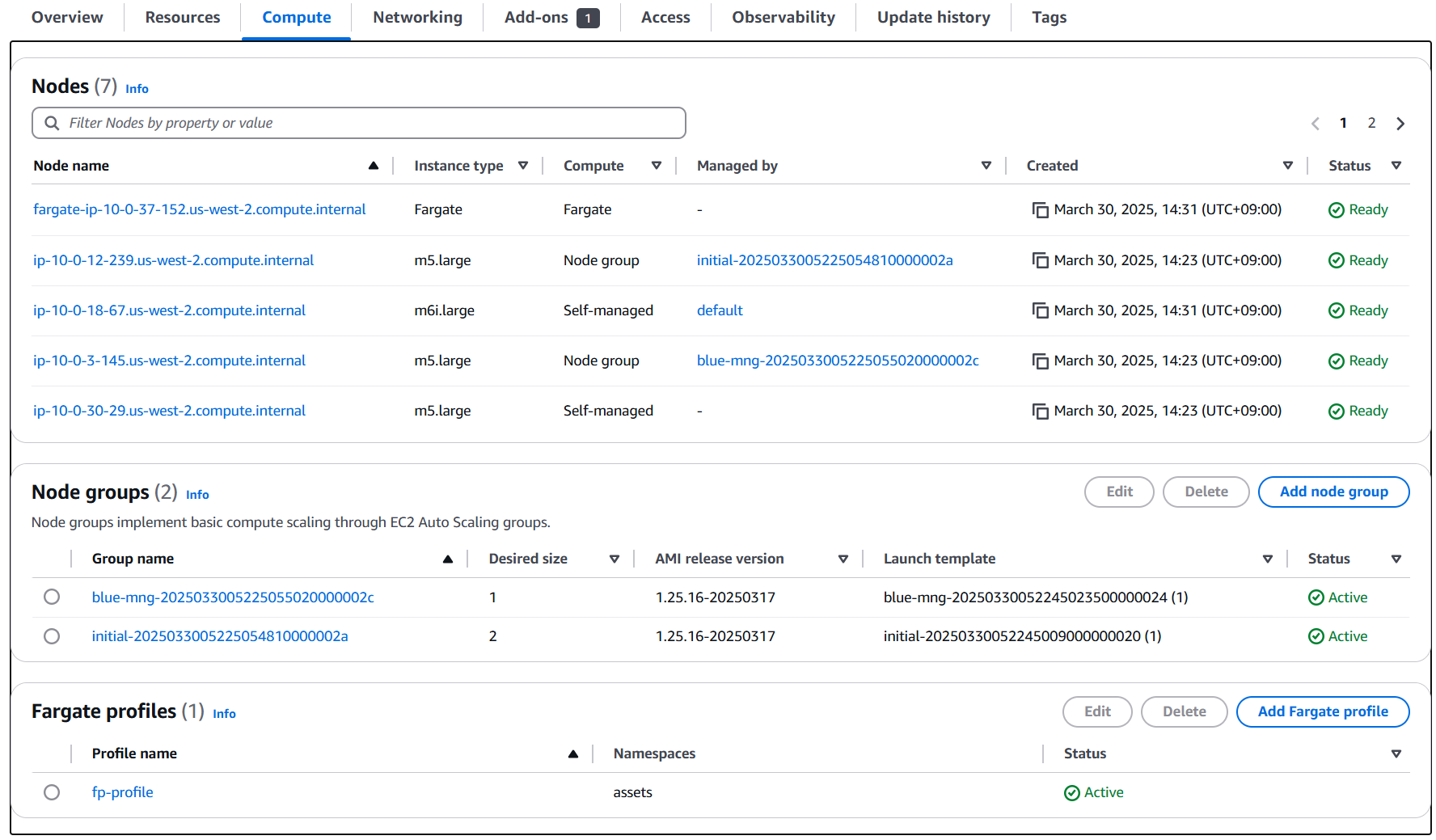
또한 Compute 정보를 살펴보면 다양한 데이터 플레인 형태를 가지고 있습니다. Nodes를 보면 2개의 Managed node가 있고, 2개의 Self-managed node가 있습니다(실제로 1개는 Karpenter 노드입니다). 그리고 Fargate 노드도 확인됩니다.
그러하므로 컨트롤 플레인을 업그레이드 한 뒤, 각 노드 그룹의 유형 별로 다른 업그레이드 방식을 실습을 통해 살펴보겠습니다.
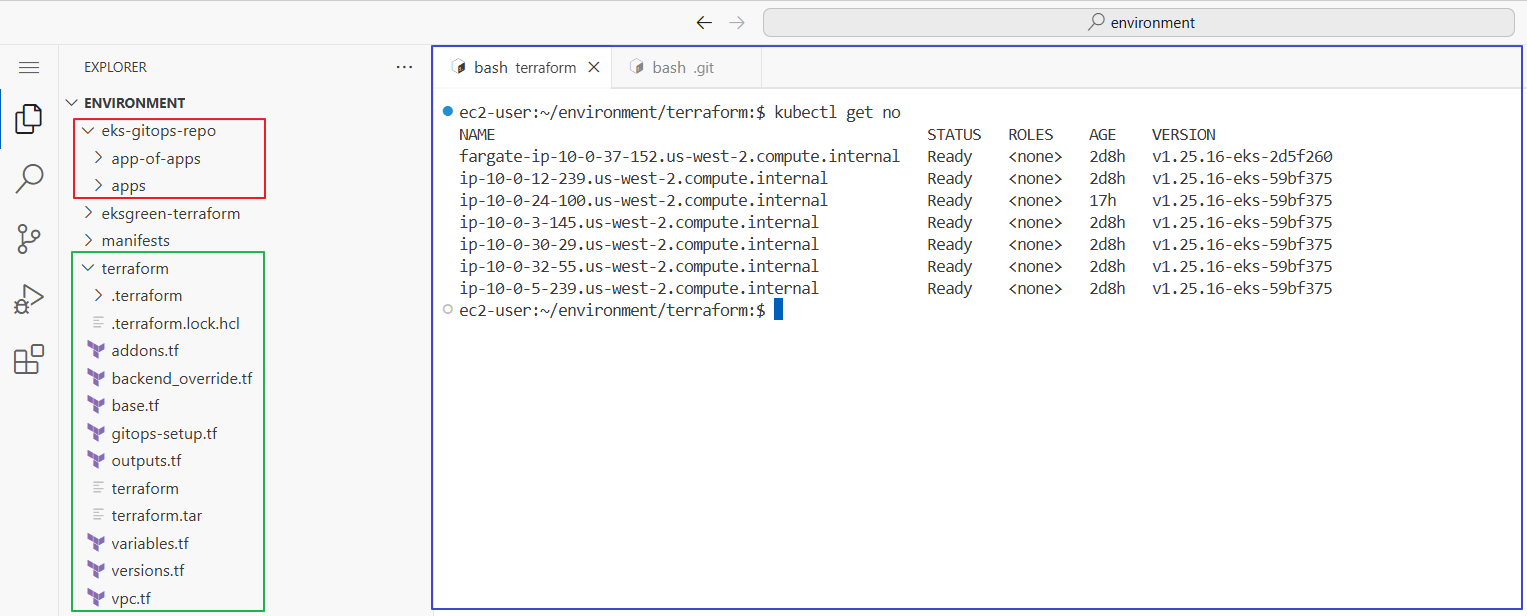
워크샵에서는 웹 콘솔뿐 아니라 code-server를 제공하며, cod-server에 접속하면 terraform 파일(녹색), git-ops-repo에 대한 로컬 파일(빨간색)이 저장되어 있습니다. code-server 우측에는 Terminal이나 파일 편집(파란색)을 할 수 있습니다.
git-ops-repo는 code commit이 remote로 지정되어 있으며, argo CD가 구성되어 code commit 리파지터리를 바라보도록 설정되어 있습니다.

그리고 EKS에서는 argo CD에 의해서 app of apps 형태로 아래와 같은 파드들이 실행 중에 있습니다.
ec2-user:~/environment/terraform:$ kubectl get application -A
NAMESPACE NAME SYNC STATUS HEALTH STATUS
argocd apps Synced Healthy
argocd assets Synced Healthy
argocd carts Synced Healthy
argocd catalog Synced Healthy
argocd checkout Synced Healthy
argocd karpenter Synced Healthy
argocd orders Synced Healthy
argocd other Synced Healthy
argocd rabbitmq Synced Healthy
argocd ui OutOfSync Healthy
ec2-user:~/environment/terraform:$ kubectl get po -A |grep -v kube-system
NAMESPACE NAME READY STATUS RESTARTS AGE
argocd argo-cd-argocd-application-controller-0 1/1 Running 0 2d8h
argocd argo-cd-argocd-applicationset-controller-74d9c9c5c7-n5k95 1/1 Running 0 2d8h
argocd argo-cd-argocd-dex-server-6dbbd57479-mst55 1/1 Running 0 2d8h
argocd argo-cd-argocd-notifications-controller-fb4b954d5-v9dw7 1/1 Running 0 2d8h
argocd argo-cd-argocd-redis-76b4c599dc-c8d2j 1/1 Running 0 2d8h
argocd argo-cd-argocd-repo-server-6b777b579d-b7ssz 1/1 Running 0 2d8h
argocd argo-cd-argocd-server-86bdbd7b89-gzm7d 1/1 Running 0 2d8h
assets assets-7ccc84cb4d-2p284 1/1 Running 0 2d8h
carts carts-7ddbc698d8-wl9k9 1/1 Running 1 (2d8h ago) 2d8h
carts carts-dynamodb-6594f86bb9-8gwpf 1/1 Running 0 2d8h
catalog catalog-857f89d57d-nrnf7 1/1 Running 3 (2d8h ago) 2d8h
catalog catalog-mysql-0 1/1 Running 0 2d8h
checkout checkout-558f7777c-z5qvh 1/1 Running 0 17h
checkout checkout-redis-f54bf7cb5-r2sdp 1/1 Running 0 17h
karpenter karpenter-74c6ffc5d9-8m6mc 1/1 Running 0 2d8h
karpenter karpenter-74c6ffc5d9-nj7lc 1/1 Running 0 2d8h
orders orders-5b97745747-7rwdl 1/1 Running 2 (2d8h ago) 2d8h
orders orders-mysql-b9b997d9d-bnbmn 1/1 Running 0 2d8h
rabbitmq rabbitmq-0 1/1 Running 0 2d8h
ui ui-5dfb7d65fc-nfrjw 1/1 Running 0 2d8h
환경을 이해하기 위해 code-comit 으로 push를 해서 argo CD로 sync가 이뤄지도록 변경을 수행해보겠습니다.
# service를 nlb로 노출
cat << EOF > ~/environment/eks-gitops-repo/apps/ui/service-nlb.yaml
apiVersion: v1
kind: Service
metadata:
annotations:
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: ip
service.beta.kubernetes.io/aws-load-balancer-scheme: internet-facing
service.beta.kubernetes.io/aws-load-balancer-type: external
labels:
app.kubernetes.io/instance: ui
app.kubernetes.io/name: ui
name: ui-nlb
namespace: ui
spec:
type: LoadBalancer
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
selector:
app.kubernetes.io/instance: ui
app.kubernetes.io/name: ui
EOF
cat << EOF > ~/environment/eks-gitops-repo/apps/ui/kustomization.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
namespace: ui
resources:
- namespace.yaml
- configMap.yaml
- serviceAccount.yaml
- service.yaml
- deployment.yaml
- hpa.yaml
- service-nlb.yaml
EOF
#
cd ~/environment/eks-gitops-repo/
git add apps/ui/service-nlb.yaml apps/ui/kustomization.yaml
git commit -m "Add to ui nlb"
git push
argocd app sync ui
...
# UI 접속 URL 확인 (1.5, 1.3 배율)
kubectl get svc -n ui ui-nlb -o jsonpath='{.status.loadBalancer.ingress[0].hostname}' | awk '{ print "UI URL = http://"$1""}'
이제 실제 업그레이드를 수행해 보겠습니다. 클러스터 업그레이드 수단은 웹 콘솔, CLI, IaC 도구 등이 있을 수 있습니다. 본 실습에서는 Terraform을 통해서 모든 업그레이드를 진행합니다.
3. In-place 클러스터 업그레이드
3.1. 컨트롤 플레인 업그레이드
EKS의 컨트롤 플레인 업그레이드는 Blue/Green 업그레이드 방식으로 진행되는 것으로 알려져 있습니다. 업그레이드 과정에서 이슈가 발생하면 업그레이드는 Roll back되어 영향을 최소화 합니다. Rollback 되는 경우 실패 이유를 평가하여 문제를 해결하기 위한 지침을 제공하여, 문제를 해결하고 다시 업그레이드를 시도할 수 있습니다.
컨트롤 플레인 업그레이드에 앞서 서비스 호출을 모니터링 하겠습니다.
export UI_WEB=$(kubectl get svc -n ui ui-nlb -o jsonpath='{.status.loadBalancer.ingress[0].hostname}'/actuator/health/liveness)
while true; do date; curl -s $UI_WEB; echo; aws eks describe-cluster --name eksworkshop-eksctl | egrep 'version|endpoint"|issuer|platformVersion'; echo ; sleep 2; echo; done
Terraform 코드에서 EKS의 버전 정보는 variables.tf 저장되어 있습니다. 여기서 cluster_version을 1.25에서 1.26으로 변경합니다.
variable "cluster_version" {
description = "EKS cluster version."
type = string
default = "1.25"
}
variable "mng_cluster_version" {
description = "EKS cluster mng version."
type = string
default = "1.25"
}
variable "ami_id" {
description = "EKS AMI ID for node groups"
type = string
default = ""
}
터미널에서 아래와 같이 수행하면 대략 10분 내에 완료가 됩니다.
ec2-user:~/environment/terraform:$ terraform apply -auto-approve
aws_iam_user.argocd_user: Refreshing state... [id=argocd-user]
module.vpc.aws_vpc.this[0]: Refreshing state... [id=vpc-0cf5ec98d2e448575]
module.eks.data.aws_partition.current[0]: Reading...
data.aws_caller_identity.current: Reading...
...
Plan: 6 to add, 13 to change, 6 to destroy.
...
...
Apply complete! Resources: 6 added, 2 changed, 6 destroyed.
Outputs:
configure_kubectl = "aws eks --region us-west-2 update-kubeconfig --name eksworkshop-eksctl"
웹 콘솔에서도 업그레이드가 트리거 된 것을 확인 할 수 있습니다.
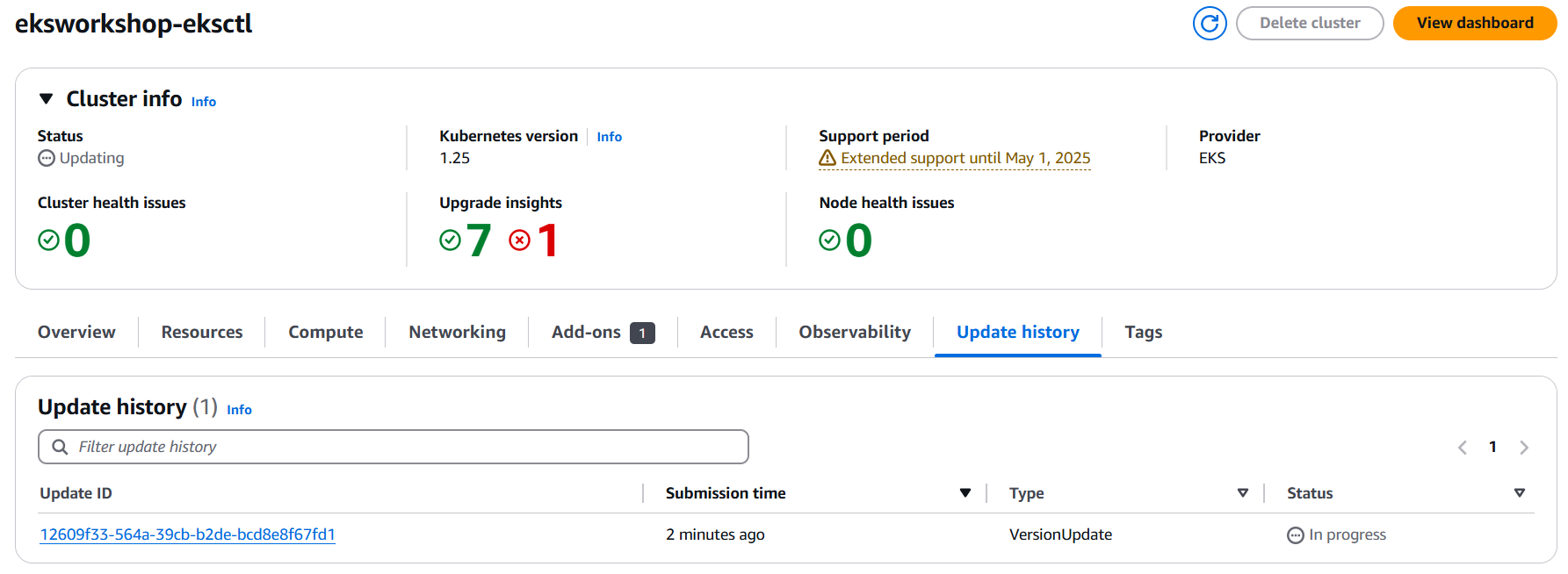
컨트롤 플레인 업그레이드 전/후 시간과 상태를 보면 아래와 같습니다.
# 업그레이드 전
Tue Apr 1 14:22:41 UTC 2025
{"status":"UP"}
"version": "1.25",
"endpoint": "https://C55B5928163C30776DEF011A92FE870C.gr7.us-west-2.eks.amazonaws.com",
"issuer": "https://oidc.eks.us-west-2.amazonaws.com/id/C55B5928163C30776DEF011A92FE870C"
"platformVersion": "eks.44",
...
Tue Apr 1 14:30:20 UTC 2025
{"status":"UP"}
"version": "1.26",
"endpoint": "https://C55B5928163C30776DEF011A92FE870C.gr7.us-west-2.eks.amazonaws.com",
"issuer": "https://oidc.eks.us-west-2.amazonaws.com/id/C55B5928163C30776DEF011A92FE870C"
"platformVersion": "eks.45",
업그레이드를 진행한 이후에 데이터 플레인의 버전과는 상이한 상태이지만, Kubernetes version skew에서는 문제가 없는 상황입니다. 아래와 같이 Upgrade insight를 확인해볼 수 있습니다.
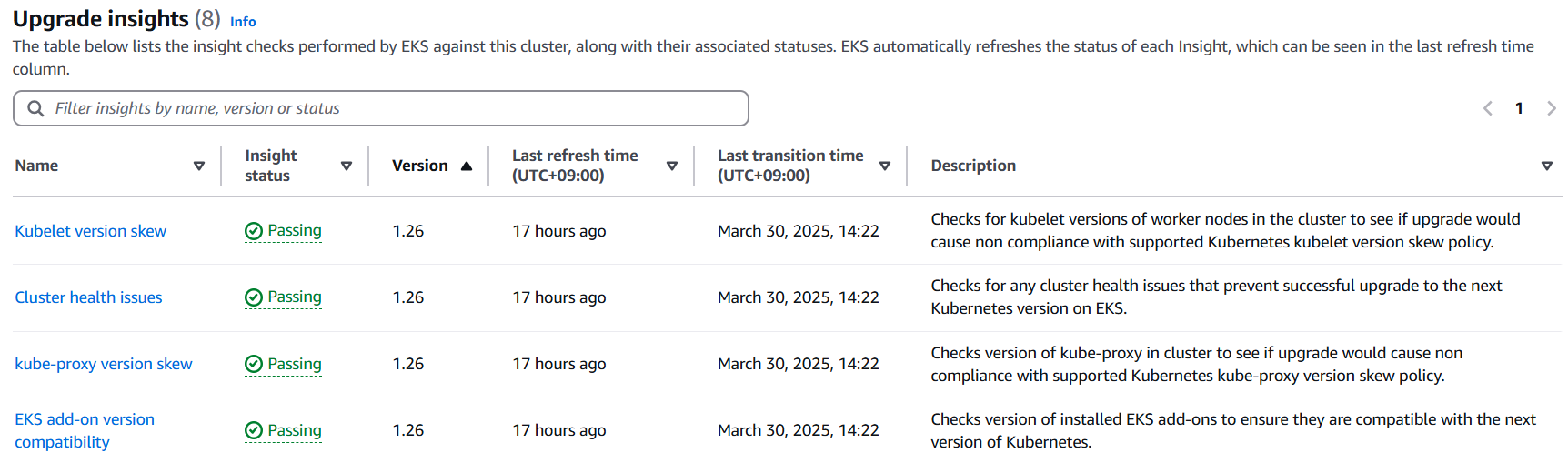
3.2. Addons 업그레이드
이제 애드온 업그레이드를 진행하겠습니다.
eksctl 을 통해서 가능한 업그레이드 버전을 확인할 수 있습니다.
NAME VERSION STATUS ISSUES IAMROLE UPDATE AVAILABLE CONFIGURATION VALUES
aws-ebs-csi-driver v1.41.0-eksbuild.1 ACTIVE 0 arn:aws:iam::181150650881:role/eksworkshop-eksctl-ebs-csi-driver-2025033005221599450000001d
coredns v1.8.7-eksbuild.10 ACTIVE 0 v1.9.3-eksbuild.22,v1.9.3-eksbuild.21,v1.9.3-eksbuild.19,v1.9.3-eksbuild.17,v1.9.3-eksbuild.15,v1.9.3-eksbuild.11,v1.9.3-eksbuild.10,v1.9.3-eksbuild.9,v1.9.3-eksbuild.7,v1.9.3-eksbuild.6,v1.9.3-eksbuild.5,v1.9.3-eksbuild.3,v1.9.3-eksbuild.2
kube-proxy v1.25.16-eksbuild.8 ACTIVE 0 v1.26.15-eksbuild.24,v1.26.15-eksbuild.19,v1.26.15-eksbuild.18,v1.26.15-eksbuild.14,v1.26.15-eksbuild.10,v1.26.15-eksbuild.5,v1.26.15-eksbuild.2,v1.26.13-eksbuild.2,v1.26.11-eksbuild.4,v1.26.11-eksbuild.1,v1.26.9-eksbuild.2,v1.26.7-eksbuild.2,v1.26.6-eksbuild.2,v1.26.6-eksbuild.1,v1.26.4-eksbuild.1,v1.26.2-eksbuild.1
vpc-cni v1.19.3-eksbuild.1 ACTIVE 0
각 애드온은 아래 페이지에서 EKS 버전 별 호환 버전을 확인하실 수 있습니다.
- Amazon VPC CNI: https://docs.aws.amazon.com/eks/latest/userguide/managing-vpc-cni.html
- coredns: https://docs.aws.amazon.com/eks/latest/userguide/managing-coredns.html
- kube-proxy: https://docs.aws.amazon.com/eks/latest/userguide/managing-kube-proxy.html
또한 아래 명령으로 1.26에 호환되는 버전 정보를 확인 할 수 있습니다. 현재 VPC CNI와 EBS CSI driver는 최신 버전을 사용 중으로 coredns(v1.8.7-eksbuild.10), kube-proxy(v1.25.16-eksbuild.8)에 대해서 확인합니다.
ec2-user:~/environment/terraform:$ aws eks describe-addon-versions --addon-name coredns --kubernetes-version 1.26 --output table \
--query "addons[].addonVersions[:10].{Version:addonVersion,DefaultVersion:compatibilities[0].defaultVersion}"
------------------------------------------
| DescribeAddonVersions |
+-----------------+----------------------+
| DefaultVersion | Version |
+-----------------+----------------------+
| False | v1.9.3-eksbuild.22 |
| False | v1.9.3-eksbuild.21 |
| False | v1.9.3-eksbuild.19 |
| False | v1.9.3-eksbuild.17 |
| False | v1.9.3-eksbuild.15 |
| False | v1.9.3-eksbuild.11 |
| False | v1.9.3-eksbuild.10 |
| False | v1.9.3-eksbuild.9 |
| True | v1.9.3-eksbuild.7 |
| False | v1.9.3-eksbuild.6 |
+-----------------+----------------------+
ec2-user:~/environment/terraform:$ aws eks describe-addon-versions --addon-name kube-proxy --kubernetes-version 1.26 --output table \
--query "addons[].addonVersions[:10].{Version:addonVersion,DefaultVersion:compatibilities[0].defaultVersion}"
--------------------------------------------
| DescribeAddonVersions |
+-----------------+------------------------+
| DefaultVersion | Version |
+-----------------+------------------------+
| False | v1.26.15-eksbuild.24 |
| False | v1.26.15-eksbuild.19 |
| False | v1.26.15-eksbuild.18 |
| False | v1.26.15-eksbuild.14 |
| False | v1.26.15-eksbuild.10 |
| False | v1.26.15-eksbuild.5 |
| False | v1.26.15-eksbuild.2 |
| False | v1.26.13-eksbuild.2 |
| False | v1.26.11-eksbuild.4 |
| False | v1.26.11-eksbuild.1 |
+-----------------+------------------------+
테라폼 코드 중 addons.tf 를 열어 아래의 정보를 최신 버전으로 변경합니다.
eks_addons = {
coredns = {
addon_version = "v1.8.7-eksbuild.10"
}
kube-proxy = {
addon_version = "v1.25.16-eksbuild.8"
}
vpc-cni = {
most_recent = true
}
aws-ebs-csi-driver = {
service_account_role_arn = module.ebs_csi_driver_irsa.iam_role_arn
}
}
terraform 명령으로 업그레이드를 진행합니다.
ec2-user:~/environment/terraform:$ terraform apply -auto-approve
aws_iam_user.argocd_user: Refreshing state... [id=argocd-user]
data.aws_caller_identity.current: Reading...
...
Apply complete! Resources: 0 added, 2 changed, 0 destroyed.
Outputs:
configure_kubectl = "aws eks --region us-west-2 update-kubeconfig --name eksworkshop-eksctl"
대략 1분 30초 정도가 소요되었습니다.
Tue Apr 1 14:58:07 UTC 2025
{"status":"UP"}
"version": "1.26",
"endpoint": "https://C55B5928163C30776DEF011A92FE870C.gr7.us-west-2.eks.amazonaws.com",
"issuer": "https://oidc.eks.us-west-2.amazonaws.com/id/C55B5928163C30776DEF011A92FE870C"
"platformVersion": "eks.45",
...
Tue Apr 1 14:59:36 UTC 2025
{"status":"UP"}
"version": "1.26",
"endpoint": "https://C55B5928163C30776DEF011A92FE870C.gr7.us-west-2.eks.amazonaws.com",
"issuer": "https://oidc.eks.us-west-2.amazonaws.com/id/C55B5928163C30776DEF011A92FE870C"
"platformVersion": "eks.45",
관련 파드들이 롤링 업데이트 됩니다. 과정을 살펴보면 coredns는 pdb가 지정되어 있기 때문에 하나의 파드가 Running 상태가 된 이후 old파드가 Terminating되는 것을 알 수 있습니다. kube-proxy는 데몬 셋으로 종료 후 신규 파드로 생성됩니다.
ec2-user:~/environment:$ kubectl get pdb -n kube-system
NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
aws-load-balancer-controller N/A 1 1 2d9h
coredns N/A 1 1 2d9h
ebs-csi-controller N/A 1 1 2d9h
ec2-user:~/environment:$ kubectl get po -n kube-system -w
NAME READY STATUS RESTARTS AGE
...
kube-proxy-rdhmw 1/1 Terminating 0 2d9h
coredns-98f76fbc4-d7l7z 1/1 Terminating 0 2d9h
kube-proxy-rdhmw 0/1 Terminating 0 2d9h
kube-proxy-rdhmw 0/1 Terminating 0 2d9h
kube-proxy-rdhmw 0/1 Terminating 0 2d9h
coredns-58cc4d964b-5rbmb 0/1 Pending 0 0s
coredns-58cc4d964b-5rbmb 0/1 Pending 0 0s
coredns-58cc4d964b-5rbmb 0/1 ContainerCreating 0 0s
coredns-58cc4d964b-d5zmg 0/1 Pending 0 0s
coredns-58cc4d964b-d5zmg 0/1 Pending 0 0s
kube-proxy-gbn46 0/1 Pending 0 1s
kube-proxy-gbn46 0/1 Pending 0 1s
coredns-58cc4d964b-d5zmg 0/1 ContainerCreating 0 0s
kube-proxy-gbn46 0/1 ContainerCreating 0 1s
coredns-98f76fbc4-d7l7z 0/1 Terminating 0 2d9h
coredns-98f76fbc4-d7l7z 0/1 Terminating 0 2d9h
coredns-98f76fbc4-d7l7z 0/1 Terminating 0 2d9h
coredns-58cc4d964b-d5zmg 0/1 Running 0 2s
coredns-58cc4d964b-d5zmg 1/1 Running 0 2s
coredns-98f76fbc4-brtkn 1/1 Terminating 0 2d9h
coredns-58cc4d964b-5rbmb 0/1 Running 0 3s
coredns-58cc4d964b-5rbmb 1/1 Running 0 3s
kube-proxy-gbn46 1/1 Running 0 3s
kube-proxy-rkvpc 1/1 Terminating 0 2d9h
coredns-98f76fbc4-brtkn 0/1 Terminating 0 2d9h
coredns-98f76fbc4-brtkn 0/1 Terminating 0 2d9h
coredns-98f76fbc4-brtkn 0/1 Terminating 0 2d9h
kube-proxy-rkvpc 0/1 Terminating 0 2d9h
kube-proxy-rkvpc 0/1 Terminating 0 2d9h
kube-proxy-rkvpc 0/1 Terminating 0 2d9h
kube-proxy-tt8mk 0/1 Pending 0 0s
kube-proxy-tt8mk 0/1 Pending 0 0s
kube-proxy-tt8mk 0/1 ContainerCreating 0 0s
kube-proxy-tt8mk 1/1 Running 0 2s
kube-proxy-psbfc 1/1 Terminating 0 2d9h
kube-proxy-psbfc 0/1 Terminating 0 2d9h
kube-proxy-psbfc 0/1 Terminating 0 2d9h
kube-proxy-psbfc 0/1 Terminating 0 2d9h
kube-proxy-vv6cz 0/1 Pending 0 0s
kube-proxy-vv6cz 0/1 Pending 0 0s
kube-proxy-vv6cz 0/1 ContainerCreating 0 0s
kube-proxy-vv6cz 1/1 Running 0 2s
kube-proxy-sv977 1/1 Terminating 0 2d9h
kube-proxy-sv977 0/1 Terminating 0 2d9h
kube-proxy-sv977 0/1 Terminating 0 2d9h
kube-proxy-sv977 0/1 Terminating 0 2d9h
kube-proxy-t9xxk 0/1 Pending 0 0s
kube-proxy-t9xxk 0/1 Pending 0 0s
kube-proxy-t9xxk 0/1 ContainerCreating 0 0s
kube-proxy-t9xxk 1/1 Running 0 2s
kube-proxy-5zz6t 1/1 Terminating 0 17h
kube-proxy-5zz6t 0/1 Terminating 0 17h
kube-proxy-5zz6t 0/1 Terminating 0 17h
kube-proxy-5zz6t 0/1 Terminating 0 17h
kube-proxy-zh6st 0/1 Pending 0 0s
kube-proxy-zh6st 0/1 Pending 0 0s
kube-proxy-zh6st 0/1 ContainerCreating 0 0s
kube-proxy-zh6st 1/1 Running 0 2s
kube-proxy-jbwlb 1/1 Terminating 0 2d9h
kube-proxy-jbwlb 0/1 Terminating 0 2d9h
kube-proxy-jbwlb 0/1 Terminating 0 2d9h
kube-proxy-jbwlb 0/1 Terminating 0 2d9h
kube-proxy-6jlqj 0/1 Pending 0 0s
kube-proxy-6jlqj 0/1 Pending 0 0s
kube-proxy-6jlqj 0/1 ContainerCreating 0 0s
kube-proxy-6jlqj 1/1 Running 0 2s
3.3. 관리형 노드 그룹 업그레이드
In-place 클러스터 업그레이드에서도 관리형 노드 그룹의 업그레이드를 In-place와 Blue/Green 업그레이드로 선택 진행할 수 있습니다.
관리형 노드 그룹 In-place 업그레이드
In-place 업그레이드는 점진적인 롤링 업그레이드로 구현되어, 새로운 노드가 먼저 ASG에 추가되고, 이후 구 노드는 cordon, drain, remove 되는 방식으로 진행됩니다.
이 과정을 설정 단계>확장 단계>업그레이드 단계>축소단계로 이해할 수 있습니다.
1) 설정 단계
최신 Lunch template 버전을 사용하도록 ASG를 업데이트하고 updateConfig 속성을 사용하여 병렬로 업그레이드할 노드의 최대 수를 결정.
참고로 updateConfig는 노드 그룹의 속성에서 확인할 수 있습니다.
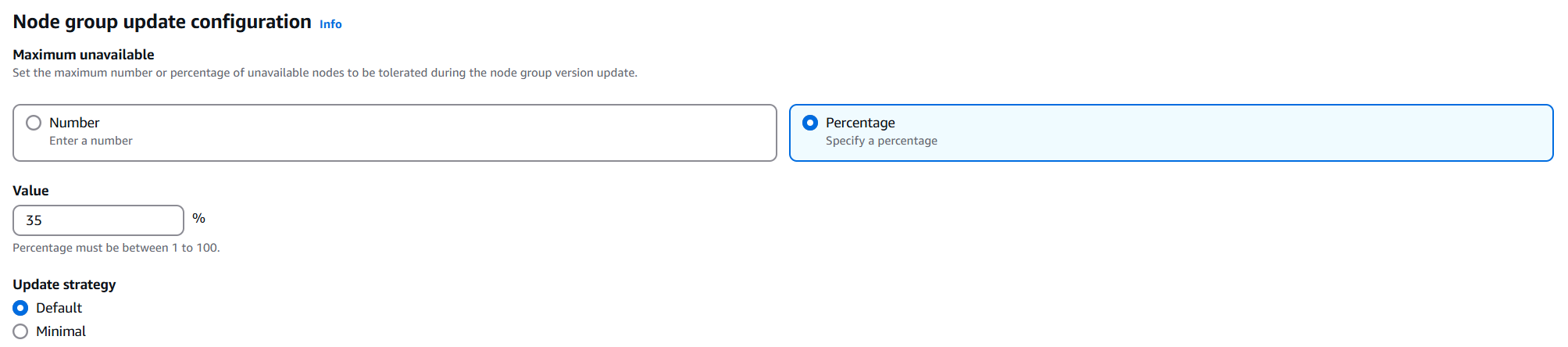
이때, Update strategy의 Default는 새 노드를 먼저 추가 후 구 노드를 삭제하는 방식이고, Minimal 구 노드를 바로 삭제하는 방식입니다. 비용이 우선시 되는 노드 그룹은 Minimal을 선택할 수 있습니다.
2) 확장 단계
ASG의 Maximum size나 desired size 중 큰 값으로 증가시킵니다. 또한 배포된 가용 영역 수의 두배까지 증가합니다.
이 단계에서 노드그룹을 확장하면 구 노드에 대해서는 un-schedulable로 마크하고, node.kubernetes.io/exclude-from-external-load-balancers=true를 설정해 로드 밸러서에서 노들르 제거할 수 있도록 합니다.
3) 업그레이드 단계
노드에서 파드 drain 하고, 노드를 cordon합니다. 이후 ASG에 종료 요청을 보냅니다. Unavailable 단위로 진행할 수 있으며, 모든 구 노드가 삭제될 때까지 업그레이드 단계를 반복합니다.
4) 축소단계
ASG의 Maximum과 Desired 를 1씩 줄여서 업데이트가 시작되기 전의 값으로 돌아갑니다.
이제 in-place 업그레이드를 진행합니다.
variable.tf 파일의 관리형 노드 그룹에 대한 값을 1.26으로 변경합니다.
variable "cluster_version" {
description = "EKS cluster version."
type = string
default = "1.26"
}
variable "mng_cluster_version" {
description = "EKS cluster mng version."
type = string
default = "1.25" # <- 1.26
}
variable "ami_id" {
description = "EKS AMI ID for node groups"
type = string
default = ""
}
마찬가지로 terraform을 적용합니다.
ec2-user:~/environment/terraform:$ terraform apply -auto-approve
...
Apply complete! Resources: 3 added, 1 changed, 3 destroyed.
Outputs:
configure_kubectl = "aws eks --region us-west-2 update-kubeconfig --name eksworkshop-eksctl"
ec2-user:~/environment/terraform:$
업그레이드 과정에서 증가/축소 및 노드 상태를 확인하기 위해서 아래와 같이 모니터링을 하겠습니다.
while true; do date; kubectl get nodes -o wide --label-columns=eks.amazonaws.com/nodegroup,topology.kubernetes.io/zone |grep initial; sleep 5; echo; done
# 최초
ec2-user:~/environment:$ while true; do date; kubectl get nodes -o wide --label-columns=eks.amazonaws.com/nodegroup,topology.kubernetes.io/zone |grep initial; sleep 5; echo; done
Tue Apr 1 15:49:52 UTC 2025
ip-10-0-12-239.us-west-2.compute.internal Ready <none> 2d10h v1.25.16-eks-59bf375 10.0.12.239 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2a
ip-10-0-32-55.us-west-2.compute.internal Ready <none> 2d10h v1.25.16-eks-59bf375 10.0.32.55 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2c
# 증가 단계 (4대의 노드가 추가 됨)
Tue Apr 1 15:53:06 UTC 2025
ip-10-0-12-239.us-west-2.compute.internal Ready <none> 2d10h v1.25.16-eks-59bf375 10.0.12.239 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2a
ip-10-0-15-190.us-west-2.compute.internal Ready <none> 27s v1.26.15-eks-59bf375 10.0.15.190 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2a
ip-10-0-28-191.us-west-2.compute.internal Ready <none> 2m27s v1.26.15-eks-59bf375 10.0.28.191 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2b
ip-10-0-30-83.us-west-2.compute.internal Ready <none> 2m26s v1.26.15-eks-59bf375 10.0.30.83 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2b
ip-10-0-32-55.us-west-2.compute.internal Ready <none> 2d10h v1.25.16-eks-59bf375 10.0.32.55 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2c
ip-10-0-46-150.us-west-2.compute.internal Ready <none> 94s v1.26.15-eks-59bf375 10.0.46.150 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2c
# 업그레이드 단계
# old node cordon
Tue Apr 1 15:53:12 UTC 2025
ip-10-0-12-239.us-west-2.compute.internal Ready,SchedulingDisabled <none> 2d10h v1.25.16-eks-59bf375 10.0.12.239 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2a
ip-10-0-15-190.us-west-2.compute.internal Ready <none> 33s v1.26.15-eks-59bf375 10.0.15.190 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2a
ip-10-0-28-191.us-west-2.compute.internal Ready <none> 2m33s v1.26.15-eks-59bf375 10.0.28.191 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2b
ip-10-0-30-83.us-west-2.compute.internal Ready <none> 2m32s v1.26.15-eks-59bf375 10.0.30.83 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2b
ip-10-0-32-55.us-west-2.compute.internal Ready,SchedulingDisabled <none> 2d10h v1.25.16-eks-59bf375 10.0.32.55 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2c
ip-10-0-46-150.us-west-2.compute.internal Ready <none> 100s v1.26.15-eks-59bf375 10.0.46.150 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2c
# x.x.x.239 old node NotReady
Tue Apr 1 15:56:07 UTC 2025
ip-10-0-12-239.us-west-2.compute.internal NotReady,SchedulingDisabled <none> 2d10h v1.25.16-eks-59bf375 10.0.12.239 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2a
ip-10-0-15-190.us-west-2.compute.internal Ready <none> 3m29s v1.26.15-eks-59bf375 10.0.15.190 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2a
ip-10-0-28-191.us-west-2.compute.internal Ready <none> 5m29s v1.26.15-eks-59bf375 10.0.28.191 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2b
ip-10-0-30-83.us-west-2.compute.internal Ready <none> 5m28s v1.26.15-eks-59bf375 10.0.30.83 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2b
ip-10-0-32-55.us-west-2.compute.internal Ready,SchedulingDisabled <none> 2d10h v1.25.16-eks-59bf375 10.0.32.55 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2c
ip-10-0-46-150.us-west-2.compute.internal Ready <none> 4m36s v1.26.15-eks-59bf375 10.0.46.150 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2c
# x.x.x.239 old node removed
Tue Apr 1 15:56:14 UTC 2025
ip-10-0-15-190.us-west-2.compute.internal Ready <none> 3m35s v1.26.15-eks-59bf375 10.0.15.190 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2a
ip-10-0-28-191.us-west-2.compute.internal Ready <none> 5m35s v1.26.15-eks-59bf375 10.0.28.191 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2b
ip-10-0-30-83.us-west-2.compute.internal Ready <none> 5m34s v1.26.15-eks-59bf375 10.0.30.83 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2b
ip-10-0-32-55.us-west-2.compute.internal Ready,SchedulingDisabled <none> 2d10h v1.25.16-eks-59bf375 10.0.32.55 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2c
ip-10-0-46-150.us-west-2.compute.internal Ready <none> 4m42s v1.26.15-eks-59bf375 10.0.46.150 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2c
# x.x.x.55 old node Not ready
Tue Apr 1 15:59:08 UTC 2025
ip-10-0-15-190.us-west-2.compute.internal Ready <none> 6m29s v1.26.15-eks-59bf375 10.0.15.190 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2a
ip-10-0-28-191.us-west-2.compute.internal Ready <none> 8m29s v1.26.15-eks-59bf375 10.0.28.191 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2b
ip-10-0-30-83.us-west-2.compute.internal Ready <none> 8m28s v1.26.15-eks-59bf375 10.0.30.83 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2b
ip-10-0-32-55.us-west-2.compute.internal NotReady,SchedulingDisabled <none> 2d10h v1.25.16-eks-59bf375 10.0.32.55 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2c
ip-10-0-46-150.us-west-2.compute.internal Ready <none> 7m36s v1.26.15-eks-59bf375 10.0.46.150 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2c
# all old nodes removed and all nodes are 1.26.15
Tue Apr 1 15:59:32 UTC 2025
ip-10-0-15-190.us-west-2.compute.internal Ready <none> 6m53s v1.26.15-eks-59bf375 10.0.15.190 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2a
ip-10-0-28-191.us-west-2.compute.internal Ready <none> 8m53s v1.26.15-eks-59bf375 10.0.28.191 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2b
ip-10-0-30-83.us-west-2.compute.internal Ready <none> 8m52s v1.26.15-eks-59bf375 10.0.30.83 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2b
ip-10-0-46-150.us-west-2.compute.internal Ready <none> 8m v1.26.15-eks-59bf375 10.0.46.150 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2c
# 축소 단계
# new node 도 cordon 상태로 빠짐
Tue Apr 1 16:00:29 UTC 2025
ip-10-0-15-190.us-west-2.compute.internal Ready <none> 7m50s v1.26.15-eks-59bf375 10.0.15.190 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2a
ip-10-0-28-191.us-west-2.compute.internal Ready <none> 9m50s v1.26.15-eks-59bf375 10.0.28.191 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2b
ip-10-0-30-83.us-west-2.compute.internal Ready,SchedulingDisabled <none> 9m49s v1.26.15-eks-59bf375 10.0.30.83 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2b
ip-10-0-46-150.us-west-2.compute.internal Ready <none> 8m57s v1.26.15-eks-59bf375 10.0.46.150 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2c
# 노드 4대 -> 3대
Tue Apr 1 16:02:22 UTC 2025
ip-10-0-15-190.us-west-2.compute.internal Ready <none> 9m43s v1.26.15-eks-59bf375 10.0.15.190 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2a
ip-10-0-28-191.us-west-2.compute.internal Ready <none> 11m v1.26.15-eks-59bf375 10.0.28.191 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2b
ip-10-0-46-150.us-west-2.compute.internal Ready <none> 10m v1.26.15-eks-59bf375 10.0.46.150 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2c
# 한대 더 corndon
Tue Apr 1 16:03:31 UTC 2025
ip-10-0-15-190.us-west-2.compute.internal Ready,SchedulingDisabled <none> 10m v1.26.15-eks-59bf375 10.0.15.190 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2a
ip-10-0-28-191.us-west-2.compute.internal Ready <none> 12m v1.26.15-eks-59bf375 10.0.28.191 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2b
ip-10-0-46-150.us-west-2.compute.internal Ready <none> 11m v1.26.15-eks-59bf375 10.0.46.150 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2c
# 최종 2대, 1.26 버전으로 업그레이드 됨
Tue Apr 1 16:05:24 UTC 2025
ip-10-0-28-191.us-west-2.compute.internal Ready <none> 14m v1.26.15-eks-59bf375 10.0.28.191 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2b
ip-10-0-46-150.us-west-2.compute.internal Ready <none> 13m v1.26.15-eks-59bf375 10.0.46.150 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 initial-2025033005225054810000002a us-west-2c
EKS의 업그레이드는 신규 노드가 추가되고 drain>cordon>drain으로 구 노드를 삭제하고, 최종 desired 수로 축소하는 방식으로 이뤄집니다. 이로 인해 결과적으로는 구 노드가 삭제되고, 신규 버전으로 생성된 신규 노드가 남는 방식으로 업그레이드가 진행됩니다.
2대 노드를 가진 노드 그룹의 업그레이드 시간은 대략 15분(15:49:52~16:05:24) 정도가 소요되었습니다.
관리형 노드 그룹 Blue/Green 업그레이드
관리형 노드 그룹도 Blue/Green 업그레이드 방식을 선택할 수 있습니다.
해당 실습에서 blue 노드 그룹은 특정 stateful 워크로드와 PV 사용으로 특정 가용 영역에만 프로비저닝이 되어 있습니다.
이 경우의 업그레이드 방식은 먼저 terraform 에 Green 관리형 노드 그룹을 생성하고, 이후 Blue 관리형 노드 그룹을 삭제하는 방식으로 진행됩니다.
먼저 base.tf에 Green 노드 그룹을 생성합니다.
eks_managed_node_groups = {
initial = {
instance_types = ["m5.large", "m6a.large", "m6i.large"]
min_size = 2
max_size = 10
desired_size = 2
update_config = {
max_unavailable_percentage = 35
}
}
blue-mng={
instance_types = ["m5.large", "m6a.large", "m6i.large"]
cluster_version = "1.25"
min_size = 1
max_size = 2
desired_size = 1
update_config = {
max_unavailable_percentage = 35
}
labels = {
type = "OrdersMNG"
}
subnet_ids = [module.vpc.private_subnets[0]] # 해당 MNG은 프라이빗서브넷1 에서 동작(ebs pv 사용 중)
taints = [
{
key = "dedicated"
value = "OrdersApp"
effect = "NO_SCHEDULE"
}
]
}
green-mng={
instance_types = ["m5.large", "m6a.large", "m6i.large"]
subnet_ids = [module.vpc.private_subnets[0]]
min_size = 1
max_size = 2
desired_size = 1
update_config = {
max_unavailable_percentage = 35
}
labels = {
type = "OrdersMNG"
}
taints = [
{
key = "dedicated"
value = "OrdersApp"
effect = "NO_SCHEDULE"
}
]
}
}
그리고 terraform apply -auto-approve을 수행하고, 노드가 증가한 상태를 확인 합니다. 동일한 가용 영역에 생성된 것을 확인할 수 있습니다.
ec2-user:~/environment:$ while true; do date; kubectl get nodes -o wide --label-columns=eks.amazonaws.com/nodegroup,topology.kubernetes.io/zone |egrep "green|blue"; sleep 5; echo; done
Tue Apr 1 16:24:49 UTC 2025
ip-10-0-3-145.us-west-2.compute.internal Ready <none> 2d11h v1.25.16-eks-59bf375 10.0.3.145 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 blue-mng-2025033005225055020000002c us-west-2a
...
Tue Apr 1 16:27:44 UTC 2025
ip-10-0-3-145.us-west-2.compute.internal Ready <none> 2d11h v1.25.16-eks-59bf375 10.0.3.145 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 blue-mng-2025033005225055020000002c us-west-2a
ip-10-0-3-227.us-west-2.compute.internal Ready <none> 40s v1.26.15-eks-59bf375 10.0.3.227 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 green-mng-20250401162553095800000007 us-west-2a
이제 base.tf에서 blue 노드 그룹을 삭제하고 terraform apply -auto-approve을 수행합니다.
현재 blue 노드 그룹에는 orders 파드들이 실행 중인 것을 알 수 있습니다.
ec2-user:~/environment:$ kubectl get po -A -owide |grep ip-10-0-3-145.us-west-2.compute.internal
kube-system aws-node-g9sk9 2/2 Running 0 2d11h 10.0.3.145 ip-10-0-3-145.us-west-2.compute.internal <none> <none>
kube-system ebs-csi-node-8jqbj 3/3 Running 0 2d11h 10.0.0.162 ip-10-0-3-145.us-west-2.compute.internal <none> <none>
kube-system efs-csi-node-x546f 3/3 Running 0 2d11h 10.0.3.145 ip-10-0-3-145.us-west-2.compute.internal <none> <none>
kube-system kube-proxy-6jlqj 1/1 Running 0 92m 10.0.3.145 ip-10-0-3-145.us-west-2.compute.internal <none> <none>
orders orders-5b97745747-7rwdl 1/1 Running 2 (2d10h ago) 2d11h 10.0.3.163 ip-10-0-3-145.us-west-2.compute.internal <none> <none>
orders orders-mysql-b9b997d9d-bnbmn 1/1 Running 0 2d11h 10.0.7.229 ip-10-0-3-145.us-west-2.compute.internal <none> <none>
노드와 이들 파드들을 모니터링 하겠습니다.
# 최초 상태
ec2-user:~/environment:$ while true; do date; kubectl get nodes -o wide --label-columns=eks.amazonaws.com/nodegroup,topology.kubernetes.io/zone |egrep "green|blue";echo; kubectl get po -A -owide |grep orders; sleep 5; echo; done
Tue Apr 1 16:34:39 UTC 2025
ip-10-0-3-145.us-west-2.compute.internal Ready <none> 2d11h v1.25.16-eks-59bf375 10.0.3.145 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 blue-mng-2025033005225055020000002c us-west-2a
ip-10-0-3-227.us-west-2.compute.internal Ready <none> 7m35s v1.26.15-eks-59bf375 10.0.3.227 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 green-mng-20250401162553095800000007 us-west-2a
orders orders-5b97745747-7rwdl 1/1 Running 2 (2d11h ago) 2d11h 10.0.3.163 ip-10-0-3-145.us-west-2.compute.internal <none> <none>
orders orders-mysql-b9b997d9d-bnbmn 1/1 Running 0 2d11h 10.0.7.229 ip-10-0-3-145.us-west-2.compute.internal <none> <none>
# Blue 노드 cordon>drain으로 Green 노드로 이전함
Tue Apr 1 16:35:04 UTC 2025
ip-10-0-3-145.us-west-2.compute.internal Ready <none> 2d11h v1.25.16-eks-59bf375 10.0.3.145 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 blue-mng-2025033005225055020000002c us-west-2a
ip-10-0-3-227.us-west-2.compute.internal Ready <none> 8m v1.26.15-eks-59bf375 10.0.3.227 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 green-mng-20250401162553095800000007 us-west-2a
orders orders-5b97745747-7rwdl 1/1 Running 2 (2d11h ago) 2d11h 10.0.3.163 ip-10-0-3-145.us-west-2.compute.internal <none> <none>
orders orders-mysql-b9b997d9d-bnbmn 1/1 Running 0 2d11h 10.0.7.229 ip-10-0-3-145.us-west-2.compute.internal <none> <none>
Tue Apr 1 16:35:11 UTC 2025
ip-10-0-3-145.us-west-2.compute.internal Ready,SchedulingDisabled <none> 2d11h v1.25.16-eks-59bf375 10.0.3.145 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 blue-mng-2025033005225055020000002c us-west-2a
ip-10-0-3-227.us-west-2.compute.internal Ready <none> 8m7s v1.26.15-eks-59bf375 10.0.3.227 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 green-mng-20250401162553095800000007 us-west-2a
orders orders-5b97745747-7ctj4 0/1 ContainerCreating 0 5s <none> ip-10-0-3-227.us-west-2.compute.internal <none> <none>
orders orders-mysql-b9b997d9d-wc9vn 0/1 ContainerCreating 0 5s <none> ip-10-0-3-227.us-west-2.compute.internal <none> <none>
# 최종 상태
Tue Apr 1 16:37:03 UTC 2025
ip-10-0-3-227.us-west-2.compute.internal Ready <none> 10m v1.26.15-eks-59bf375 10.0.3.227 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25 green-mng-20250401162553095800000007 us-west-2a
orders orders-5b97745747-7ctj4 1/1 Running 2 (81s ago) 118s 10.0.8.104 ip-10-0-3-227.us-west-2.compute.internal <none> <none>
orders orders-mysql-b9b997d9d-wc9vn 1/1 Running 0 118s 10.0.12.108 ip-10-0-3-227.us-west-2.compute.internal <none> <none>
관리형 노드 그룹에 대한 실습을 마무리 하겠습니다.
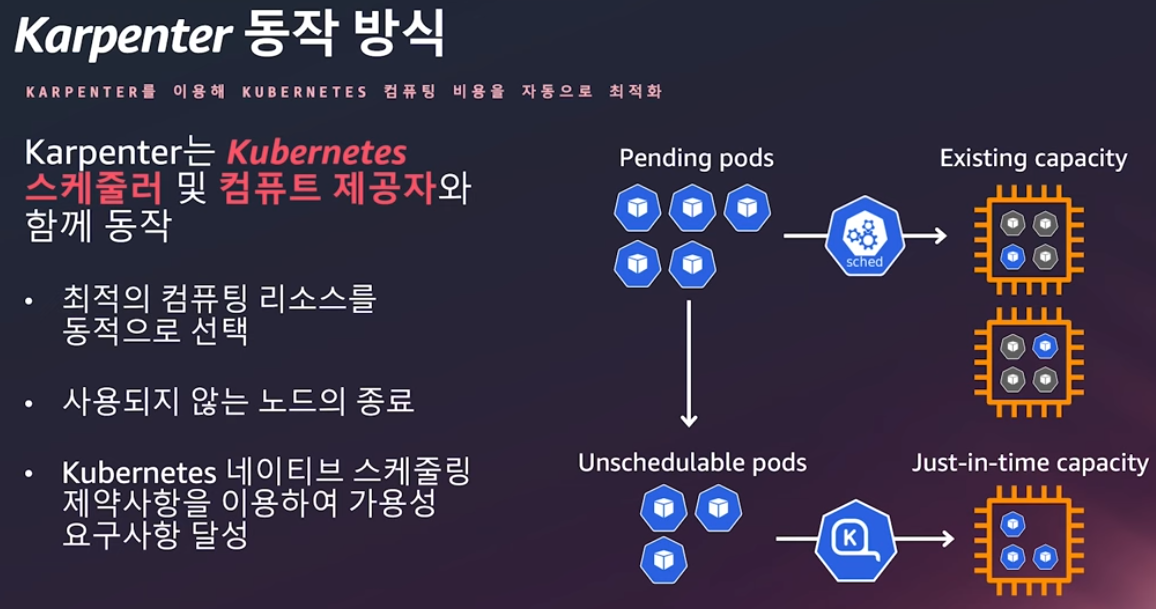
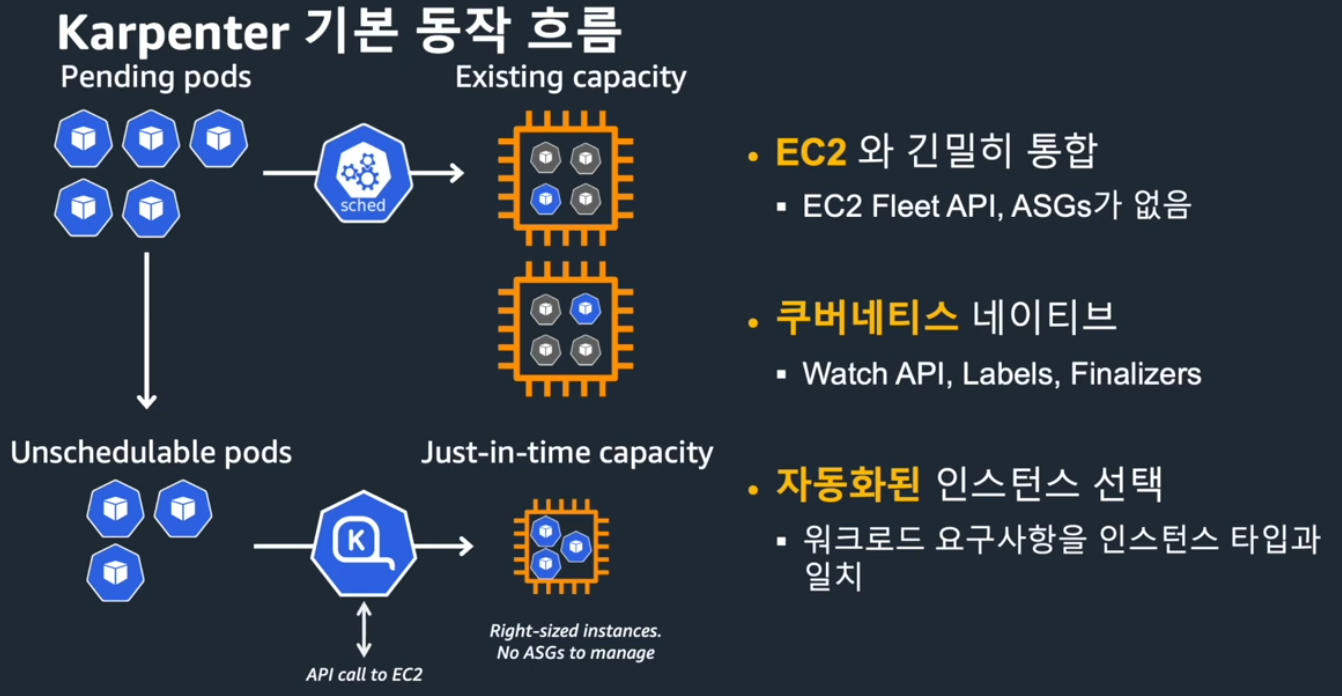
3.4. Karpenter 노드 업그레이드
앞서 살펴본 실습에서 EBS PV를 사용하는 경우와 같이 관리형 노드 그룹을 사용하는 경우에는 신규 노드 그룹을 생성하는 시점 고려하는 사항이 많습니다.
반면 Karpenter 노드는 내부적으로 신규 노드를 추가하는 시점 이러한 PV의 위치까지 고려하여 보다 사용 편의가 높습니다.
Karpenter에서는 노드 업그레이드를 위해서 Drift 혹은 TTL(expireAfter)과 같은 기능을 사용할 수 있습니다. 동작 방식이 다를 뿐 결과적으로는 EC2NodeClass에 업그레이드할 AMI로 변경하면, 원하는 사양으로 유도하거나 혹은 TTL이 지난 시점 변경되도록 하는 방식입니다.
그러하므로 이 실습은 terraform이 아닌 EC2NodeClass를 수정하는 방식을 사용합니다.
여기서는 code commit과 argoCD가 연결되어 있기 때문에, 로컬에서 수정하고 code commit으로 push한 뒤 karpenter 애플리케이션을 sync하도록 하겠습니다.
먼저 1.26에 해당하는 AMI ID를 확인합니다.
## AMI ID 확인
ec2-user:~/environment/terraform:$ aws ssm get-parameter --name /aws/service/eks/optimized-ami/1.26/amazon-linux-2/recommended/image_id \
--region ${AWS_REGION} --query "Parameter.Value" --output text
ami-086414611b43bb691
이후 로컬의 eks-gitops-repo\apps\karpenter로 이동하여 default-ec2nc.yaml의 AMI ID를 확인한 AMI ID로 변경합니다.
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
metadata:
name: default
spec:
amiFamily: AL2
amiSelectorTerms:
- id: "ami-0ee947a6f4880da75" # Latest EKS 1.25 AMI
role: karpenter-eksworkshop-eksctl
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: eksworkshop-eksctl
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: eksworkshop-eksctl
tags:
intent: apps
managed-by: karpenter
team: checkout
변경된 파일을 code commit으로 push하고, argo CD를 sync 합니다.
# 10분 소요 (예상) 실습 포함
cd ~/environment/eks-gitops-repo
git add apps/karpenter/default-ec2nc.yaml apps/karpenter/default-np.yaml
git commit -m "disruption changes"
git push --set-upstream origin main
argocd app sync karpenter
# 모니터링
while true; do date; kubectl get nodeclaim; echo ; kubectl get nodes -l team=checkout; echo ; kubectl get nodes -l team=checkout -o jsonpath="{range .items[*]}{.metadata.name} {.spec.taints}{\"\n\"}{end}"; echo ; kubectl get pods -n checkout -o wide; echo ; sleep 1; echo; done
# 최초 상태
ec2-user:~/environment:$
while true; do date; kubectl get nodeclaim; echo ; kubectl get nodes -l team=checkout; echo ; kubectec2-user:~/environment:$ while true; do date; kubectl get nodeclaim; echo ; kubectl get nodes -l team=checkout; echo ; kubectl get nodes -l team=checkout -o jsonpath="{range .items[*]}{.metadata.name} {.spec.taints}{\"\n\"}{end}"; echo ; kubectl get pods -n checkout -o wide; echo ; sleep 1; echo; done
Tue Apr 1 16:54:08 UTC 2025
NAME TYPE ZONE NODE READY AGE
default-6css4 c4.large us-west-2b ip-10-0-24-100.us-west-2.compute.internal True 19h
NAME STATUS ROLES AGE VERSION
ip-10-0-24-100.us-west-2.compute.internal Ready <none> 19h v1.25.16-eks-59bf375
ip-10-0-24-100.us-west-2.compute.internal [{"effect":"NoSchedule","key":"dedicated","value":"CheckoutApp"}]
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
checkout-558f7777c-z5qvh 1/1 Running 0 19h 10.0.29.195 ip-10-0-24-100.us-west-2.compute.internal <none> <none>
checkout-redis-f54bf7cb5-r2sdp 1/1 Running 0 19h 10.0.19.67 ip-10-0-24-100.us-west-2.compute.internal <none> <none>
# 신규 노드 생성
Tue Apr 1 16:58:58 UTC 2025
NAME TYPE ZONE NODE READY AGE
default-6css4 c4.large us-west-2b ip-10-0-24-100.us-west-2.compute.internal True 19h
default-pflq6 c4.large us-west-2b Unknown 3s
NAME STATUS ROLES AGE VERSION
ip-10-0-24-100.us-west-2.compute.internal Ready <none> 19h v1.25.16-eks-59bf375
# 노드 Ready
Tue Apr 1 17:00:35 UTC 2025
NAME TYPE ZONE NODE READY AGE
default-6css4 c4.large us-west-2b ip-10-0-24-100.us-west-2.compute.internal True 19h
default-pflq6 c4.large us-west-2b ip-10-0-28-136.us-west-2.compute.internal True 99s
NAME STATUS ROLES AGE VERSION
ip-10-0-24-100.us-west-2.compute.internal Ready <none> 19h v1.25.16-eks-59bf375
ip-10-0-28-136.us-west-2.compute.internal Ready <none> 27s v1.26.15-eks-59bf375
# 신규 노드로 파드 생성
Tue Apr 1 17:00:35 UTC 2025
NAME TYPE ZONE NODE READY AGE
default-6css4 c4.large us-west-2b ip-10-0-24-100.us-west-2.compute.internal True 19h
default-pflq6 c4.large us-west-2b ip-10-0-28-136.us-west-2.compute.internal True 99s
NAME STATUS ROLES AGE VERSION
ip-10-0-24-100.us-west-2.compute.internal Ready <none> 19h v1.25.16-eks-59bf375
ip-10-0-28-136.us-west-2.compute.internal Ready <none> 27s v1.26.15-eks-59bf375
ip-10-0-24-100.us-west-2.compute.internal [{"effect":"NoSchedule","key":"dedicated","value":"CheckoutApp"},{"effect":"NoSchedule","key":"karpenter.sh/disruption","value":"disrupting"}]
ip-10-0-28-136.us-west-2.compute.internal [{"effect":"NoSchedule","key":"dedicated","value":"CheckoutApp"}]
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
checkout-558f7777c-z5qvh 1/1 Running 0 19h 10.0.29.195 ip-10-0-24-100.us-west-2.compute.internal <none> <none>
checkout-redis-f54bf7cb5-r2sdp 1/1 Running 0 19h 10.0.19.67 ip-10-0-24-100.us-west-2.compute.internal <none> <none>
Tue Apr 1 17:00:41 UTC 2025
NAME TYPE ZONE NODE READY AGE
default-6css4 c4.large us-west-2b ip-10-0-24-100.us-west-2.compute.internal True 19h
default-pflq6 c4.large us-west-2b ip-10-0-28-136.us-west-2.compute.internal True 105s
NAME STATUS ROLES AGE VERSION
ip-10-0-24-100.us-west-2.compute.internal Ready <none> 19h v1.25.16-eks-59bf375
ip-10-0-28-136.us-west-2.compute.internal Ready <none> 33s v1.26.15-eks-59bf375
ip-10-0-24-100.us-west-2.compute.internal [{"effect":"NoSchedule","key":"dedicated","value":"CheckoutApp"},{"effect":"NoSchedule","key":"karpenter.sh/disruption","value":"disrupting"}]
ip-10-0-28-136.us-west-2.compute.internal [{"effect":"NoSchedule","key":"dedicated","value":"CheckoutApp"}]
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
checkout-558f7777c-hddnc 0/1 ContainerCreating 0 2s <none> ip-10-0-28-136.us-west-2.compute.internal <none> <none>
checkout-redis-f54bf7cb5-tqj6q 0/1 ContainerCreating 0 2s <none> ip-10-0-28-136.us-west-2.compute.internal <none> <none>
# 구 노드 사라짐
Tue Apr 1 17:00:46 UTC 2025
NAME TYPE ZONE NODE READY AGE
default-pflq6 c4.large us-west-2b ip-10-0-28-136.us-west-2.compute.internal True 109s
NAME STATUS ROLES AGE VERSION
ip-10-0-28-136.us-west-2.compute.internal Ready <none> 37s v1.26.15-eks-59bf375
ip-10-0-28-136.us-west-2.compute.internal [{"effect":"NoSchedule","key":"dedicated","value":"CheckoutApp"}]
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
checkout-558f7777c-hddnc 0/1 ContainerCreating 0 6s <none> ip-10-0-28-136.us-west-2.compute.internal <none> <none>
checkout-redis-f54bf7cb5-tqj6q 0/1 ContainerCreating 0 6s <none> ip-10-0-28-136.us-west-2.compute.internal <none> <none>
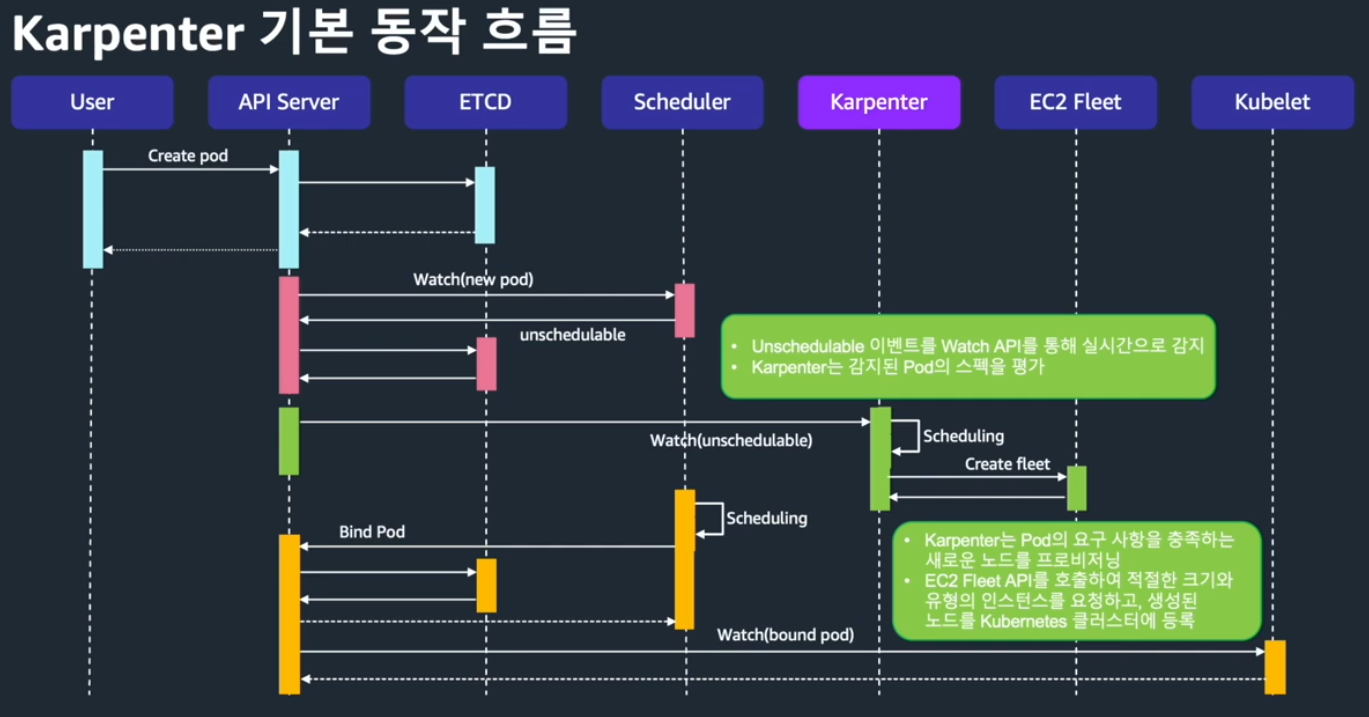
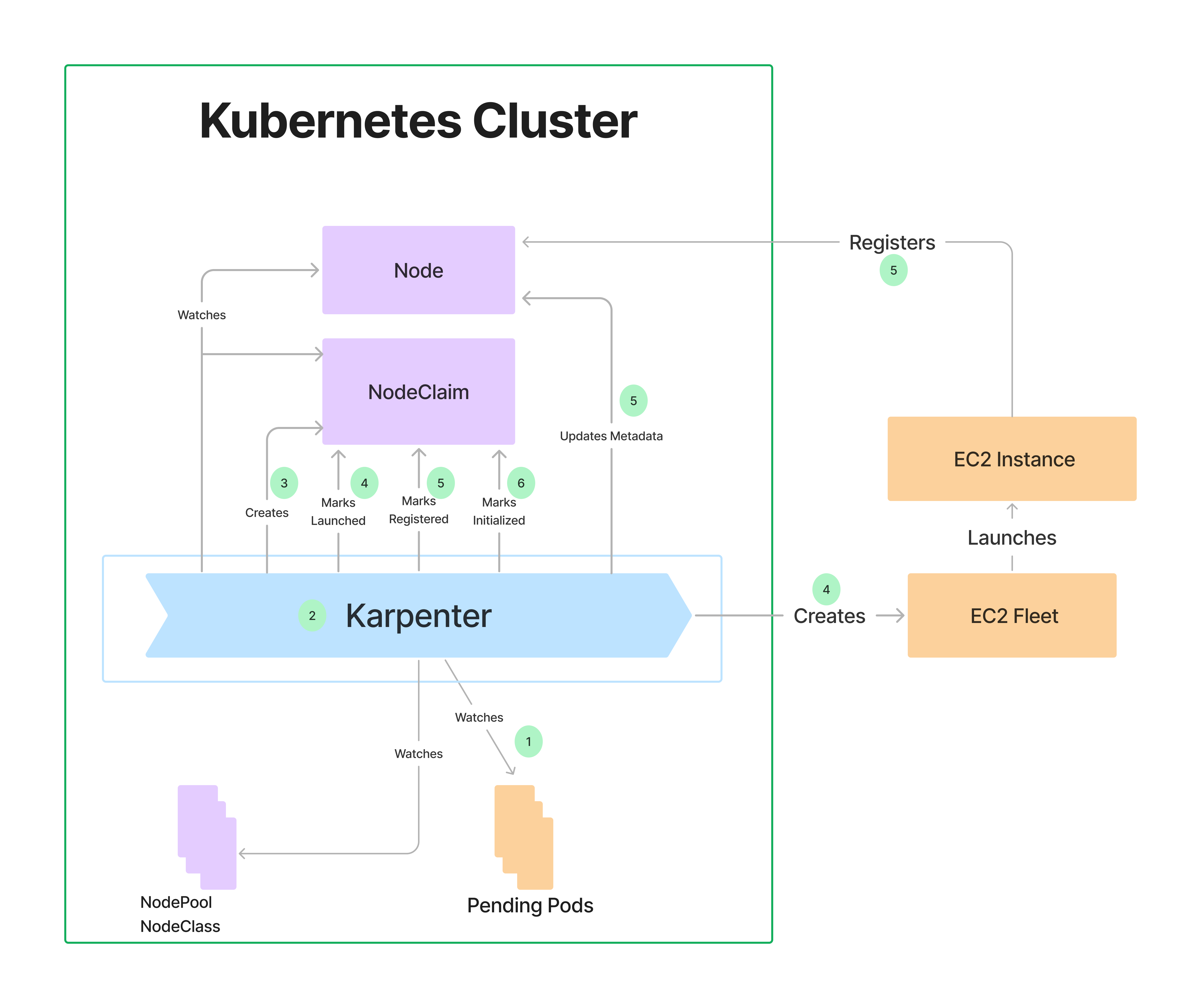
Karpenter 동작의 세부 과정은 로그를 통해서 확인할 수 있습니다.
kubectl -n karpenter logs deployment/karpenter -c controller --tail=33 -f
...
# drift 진행 > nodeClaim 생성 > nodeClaim launch
{"level":"INFO","time":"2025-04-01T16:58:57.282Z","logger":"controller","message":"disrupting via drift replace, terminating 1 nodes (2 pods) ip-10-0-24-100.us-west-2.compute.internal/c4.large/spot and replacing with node from types c5.large, c4.large, m6a.large, r4.large, m6i.large and 40 other(s)","commit":"490ef94","controller":"disruption","command-id":"3a295ac9-2a0d-4ddf-a6cb-e8d08915cff2"}
{"level":"INFO","time":"2025-04-01T16:58:57.318Z","logger":"controller","message":"created nodeclaim","commit":"490ef94","controller":"disruption","NodePool":{"name":"default"},"NodeClaim":{"name":"default-pflq6"},"requests":{"cpu":"430m","memory":"632Mi","pods":"6"},"instance-types":"c4.2xlarge, c4.4xlarge, c4.8xlarge, c4.large, c4.xlarge and 40 other(s)"}
{"level":"INFO","time":"2025-04-01T16:59:00.052Z","logger":"controller","message":"launched nodeclaim","commit":"490ef94","controller":"nodeclaim.lifecycle","controllerGroup":"karpenter.sh","controllerKind":"NodeClaim","NodeClaim":{"name":"default-pflq6"},"namespace":"","name":"default-pflq6","reconcileID":"a314c3cc-925a-4039-a313-b10e3d762fed","provider-id":"aws:///us-west-2b/i-05f149a8dcf7d844d","instance-type":"c4.large","zone":"us-west-2b","capacity-type":"spot","allocatable":{"cpu":"1930m","ephemeral-storage":"17Gi","memory":"2878Mi","pods":"29"}}
# 노드 register > initialize
{"level":"INFO","time":"2025-04-01T17:00:10.779Z","logger":"controller","message":"registered nodeclaim","commit":"490ef94","controller":"nodeclaim.lifecycle","controllerGroup":"karpenter.sh","controllerKind":"NodeClaim","NodeClaim":{"name":"default-pflq6"},"namespace":"","name":"default-pflq6","reconcileID":"5a16a55e-9a6f-434f-b59e-c7daf0a93bf3","provider-id":"aws:///us-west-2b/i-05f149a8dcf7d844d","Node":{"name":"ip-10-0-28-136.us-west-2.compute.internal"}}
{"level":"INFO","time":"2025-04-01T17:00:33.021Z","logger":"controller","message":"initialized nodeclaim","commit":"490ef94","controller":"nodeclaim.lifecycle","controllerGroup":"karpenter.sh","controllerKind":"NodeClaim","NodeClaim":{"name":"default-pflq6"},"namespace":"","name":"default-pflq6","reconcileID":"c4e40956-a02a-4337-bd69-6b9be1d72d5f","provider-id":"aws:///us-west-2b/i-05f149a8dcf7d844d","Node":{"name":"ip-10-0-28-136.us-west-2.compute.internal"},"allocatable":{"cpu":"1930m","ephemeral-storage":"18242267924","hugepages-1Gi":"0","hugepages-2Mi":"0","memory":"3119300Ki","pods":"29"}}
{"level":"INFO","time":"2025-04-01T17:00:42.921Z","logger":"controller","message":"command succeeded","commit":"490ef94","controller":"disruption.queue","command-id":"3a295ac9-2a0d-4ddf-a6cb-e8d08915cff2"}
# 노드 삭제
{"level":"INFO","time":"2025-04-01T17:00:42.963Z","logger":"controller","message":"tainted node","commit":"490ef94","controller":"node.termination","controllerGroup":"","controllerKind":"Node","Node":{"name":"ip-10-0-24-100.us-west-2.compute.internal"},"namespace":"","name":"ip-10-0-24-100.us-west-2.compute.internal","reconcileID":"73867503-c843-4373-b03e-a3406d6f60b3"}
{"level":"INFO","time":"2025-04-01T17:00:45.441Z","logger":"controller","message":"deleted node","commit":"490ef94","controller":"node.termination","controllerGroup":"","controllerKind":"Node","Node":{"name":"ip-10-0-24-100.us-west-2.compute.internal"},"namespace":"","name":"ip-10-0-24-100.us-west-2.compute.internal","reconcileID":"03122384-44e7-4a0b-b28b-372ec6e10f1b"}
{"level":"INFO","time":"2025-04-01T17:00:45.808Z","logger":"controller","message":"deleted nodeclaim","commit":"490ef94","controller":"nodeclaim.termination","controllerGroup":"karpenter.sh","controllerKind":"NodeClaim","NodeClaim":{"name":"default-6css4"},"namespace":"","name":"default-6css4","reconcileID":"85396b01-d267-4a9a-b995-fcabaaf5e423","Node":{"name":"ip-10-0-24-100.us-west-2.compute.internal"},"provider-id":"aws:///us-west-2b/i-0cc37fd17692cedac"}
Karpenter의 Drift 방식으로 업그레이드가 완료되었습니다.
3.5. Self-managed 노드 업그레이드
Self-managed 노드 업그레이드는 사용자가 직접 AMI를 업데이트 해야하며, 이후 변경된 AMI ID를 업데이트 하는 방식으로 업그레이드를 수행합니다.
base.tf의 에서 self-managed 노드 그룹의 ami_id를 변경하고, terraform apply -auto-approve를 통해서 적용합니다.
self_managed_node_groups = {
self-managed-group = {
instance_type = "m5.large"
...
# Additional configurations
ami_id = "ami-086414611b43bb691" # Replaced the latest AMI ID for EKS 1.26
subnet_ids = module.vpc.private_subnets
.
.
.
launch_template_use_name_prefix = true
}
}
이후 노드가 변경된 것을 확인할 수 있습니다. 다만 terraform apply 이 종료된 것 처럼 보이지만, 실제 노드 그룹이 재생성 되는 시간은 조금 더 걸리는 것으로 확인됩니다. 관리형 노드 그룹은 terraform apply가 종료되는 시점과 업그레이드가 일치하지만, Self-managed 노드 업그레이드는 terraform apply가 종료되는 시점과 다르다는 점에 차이가 있습니다.
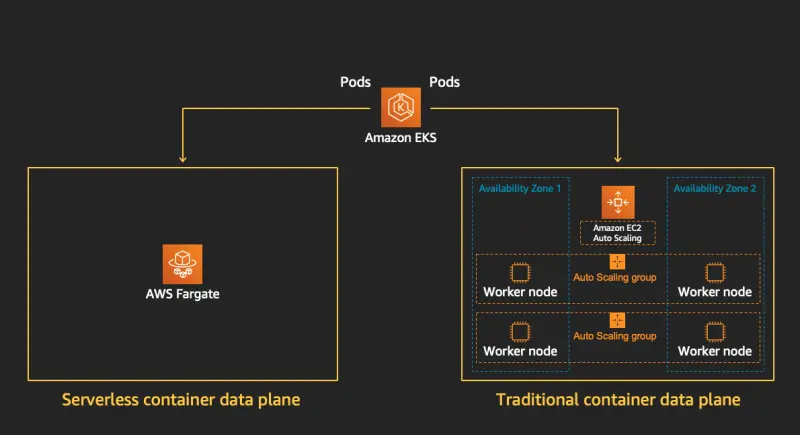
3.6. Fargate 노드 업그레이드
Fargate는 가상 머신 그룹을 직접 프로비저닝하거나 관리할 필요가 없습니다. 그러하므로, 업그레이드를 하려면 단순히 파드를 재시작해 Fargate 컨트롤러가 최신 쿠버네티스 버전으로 업데이트를 하도록 예약합니다.
아래와 같이 진행 합니다.
# 최초 상태
ec2-user:~/environment:$ kubectl get pods -n assets -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
assets-7ccc84cb4d-2p284 1/1 Running 0 2d11h 10.0.37.152 fargate-ip-10-0-37-152.us-west-2.compute.internal <none> <none>
ec2-user:~/environment:$ kubectl get node $(kubectl get pods -n assets -o jsonpath='{.items[0].spec.nodeName}') -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
fargate-ip-10-0-37-152.us-west-2.compute.internal Ready <none> 2d11h v1.25.16-eks-2d5f260 10.0.37.152 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25
# 디플로이먼트 재시작
ec2-user:~/environment:$ kubectl rollout restart deployment assets -n assets
deployment.apps/assets restarted
신규 파드가 Running 상태가 되면 노드 또한 1.26.15로 변경된 것을 알 수 있습니다.
ec2-user:~/environment:$ kubectl get pods -n assets -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
assets-66c4799cfc-4s7s6 1/1 Running 0 78s 10.0.28.67 fargate-ip-10-0-28-67.us-west-2.compute.internal <none> <none>
ec2-user:~/environment:$ kubectl get node $(kubectl get pods -n assets -o jsonpath='{.items[0].spec.nodeName}') -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
fargate-ip-10-0-28-67.us-west-2.compute.internal Ready <none> 33s v1.26.15-eks-2d5f260 10.0.28.67 <none> Amazon Linux 2 5.10.234-225.910.amzn2.x86_64 containerd://1.7.25
여기까지 In-place 클러스터 업그레이드를 살펴봤습니다.
모든 노드들이 1.26.15 버전으로 업그레이드가 완료되었습니다.
ec2-user:~/environment:$ kubectl get no
NAME STATUS ROLES AGE VERSION
fargate-ip-10-0-28-67.us-west-2.compute.internal Ready <none> 10m v1.26.15-eks-2d5f260
ip-10-0-28-136.us-west-2.compute.internal Ready <none> 27m v1.26.15-eks-59bf375
ip-10-0-28-191.us-west-2.compute.internal Ready <none> 96m v1.26.15-eks-59bf375
ip-10-0-3-227.us-west-2.compute.internal Ready <none> 60m v1.26.15-eks-59bf375
ip-10-0-31-15.us-west-2.compute.internal Ready <none> 7m9s v1.26.15-eks-59bf375
ip-10-0-35-1.us-west-2.compute.internal Ready <none> 12m v1.26.15-eks-59bf375
ip-10-0-46-150.us-west-2.compute.internal Ready <none> 95m v1.26.15-eks-59bf375
4. Blue/Green 클러스터 업그레이드
Blue/Green 클러스터 업그레이드는 앞서 살펴본 관리형 노드 그룹의 Blue/Green 업그레이드와 동일합니다. 신규 Green 클러스터를 생성하고, 이후 트래픽을 라우팅 하는 방식으로 업그레이드를 완료할 수 있습니다.
결국 In-place와의 차이점은 Blue/Green 클러스터는 별개의 클러스터이기 때문에 한번에 원하는 버전으로 업그레이드를 할 수 있다는 장점이 있습니다. 또한 기존 클러스터를 유지하여 간단하게 Rollback을 가능하게 합니다. 다만 동시에 2개 클러스터를 구성하게 되어 추가 비용이 발생할 수 있다는 점과 신규 클러스터로 Stateful 워크로드의 이전과 트래픽 라우팅의 복잡성이 존재합니다.
실습 방식 자체는 어렵지 않기 때문에 워크샵의 대략적인 개요만 설명드리겠습니다.
1) Green 클러스터 생성: Terraform 코드로 생성하고 배포 합니다. 사전에 적합한 쿠버네티스 버전과 대응하는 애드온을 업데이트 해야합니다.
2) Stateless 워크로드 마이그레이션: 상태가 없는 애플리케이션은 신규 클러스터에 배포합니다. 다만 업그레이드 버전에 deprecated API 등이 없는지 확인 후 미리 변경해야 합니다.
3) Stateful 워크로드 마이그레이션: Sateful 워크로드는 데이터 동기화 이슈가 있습니다. 이 때문에 사전에 스토리지 동기화나 데이터 동기화를 통해서 신규 클러스터에서 동일한 상태를 가지도록 해야 합니다. 이 부분은 간단하지 않기 때문에 많은 고민이 필요해 보입니다.
4) 트래픽 전환: 신규 클러스터 구성이 완료되면 트래픽을 Green으로 라우팅 합니다.
그럼 이상으로 EKS Upgrade 에 대한 포스트를 마무리 하겠습니다.
'EKS' 카테고리의 다른 글
| [7] EKS Fargate (0) | 2025.03.23 |
|---|---|
| [6] EKS의 Security - EKS 인증/인가와 Pod IAM 권한 할당 (0) | 2025.03.16 |
| [5-2] EKS의 오토스케일링 Part2 (0) | 2025.03.07 |
| [5-1] EKS의 오토스케일링 Part1 (0) | 2025.03.07 |
| [4] EKS의 모니터링과 로깅 (0) | 2025.03.01 |