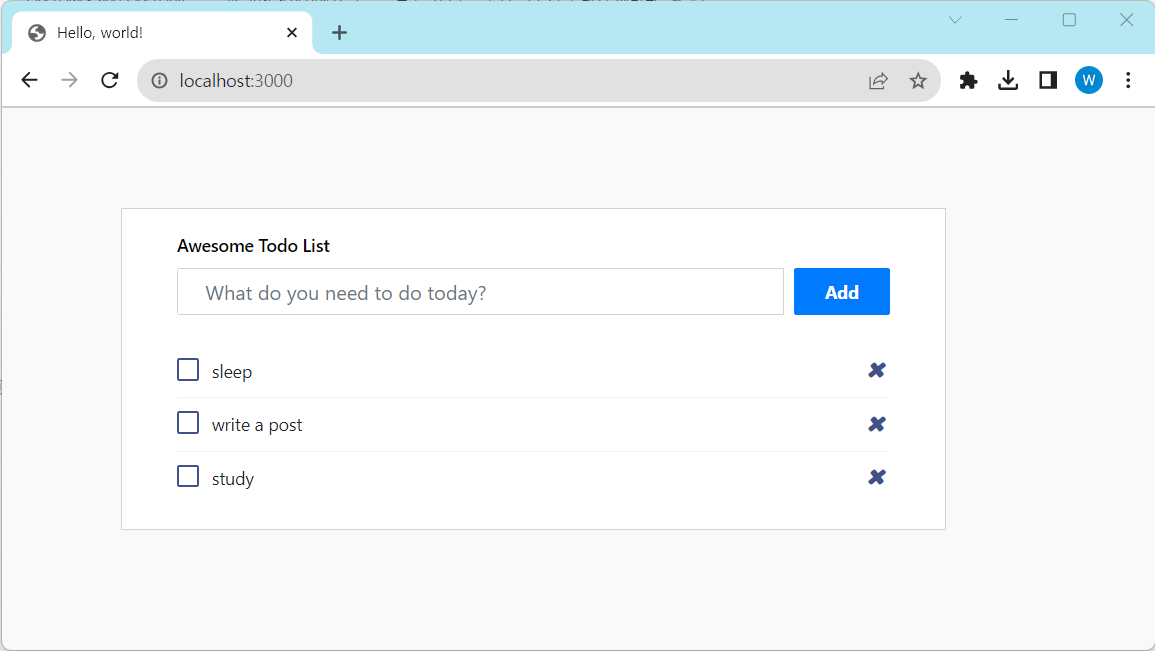
시작 하기 전에 웹서버를 만들기 앞서 gorilla/mux 외 두 가지 패키지를 더 설치한다.
urfave/negroni 패키지: 자주 사용되는 웹 핸들러를 제공하는 패키지이다. 추가로 로그 기능, panic 복구 기능, 파일 서버 기능을 제공한다.
unrolled/render 패키지: 웹 서버 응답으로 HTML, JSON, TEXT 같은 포맷을 간단히 사용할 수 있다.
$ go mod init goprojects/todo31
$ go get github.com/gorilla/mux
$ go get github.com/urfave/negroni
$ go get github.com/unrolled/render
이제 백엔드의 RESTful API를 아래와 같이 작성한다.
// ch31/ex31.1/ex31.1.go
package main
import (
"encoding/json"
"log"
"net/http"
"sort"
"strconv"
"github.com/gorilla/mux"
"github.com/unrolled/render"
"github.com/urfave/negroni"
)
var rd *render.Render
type Todo struct { // 할 일 정보를 담는 Todo 구조체
ID int `json:"id,omitempty"` // json 포맷으로 변환 옵션 -> JSON 포맷으로 변환시 ID가 아닌 id로 변환됨
Name string `json:"name"`
Completed bool `json:"completed,omitempty"`
}
var todoMap map[int]Todo
var lastID int = 0
func MakeWebHandler() http.Handler { // 웹 서버 핸들러 생성
rd = render.New()
todoMap = make(map[int]Todo)
mux := mux.NewRouter()
mux.Handle("/", http.FileServer(http.Dir("public"))) // "/"" 경로에 요청이 들어올 때 public 아래 폴더의 파일을 제공하는 파일 서버
// "/todos" 에 대해서 GET, POST, DELETE, PUT에 대한 핸들러 구현
mux.HandleFunc("/todos", GetTodoListHandler).Methods("GET")
mux.HandleFunc("/todos", PostTodoHandler).Methods("POST")
mux.HandleFunc("/todos/{id:[0-9]+}", RemoveTodoHandler).Methods("DELETE")
mux.HandleFunc("/todos/{id:[0-9]+}", UpdateTodoHandler).Methods("PUT")
return mux
}
type Todos []Todo // ID로 정렬하는 인터페이스
func (t Todos) Len() int {
return len(t)
}
func (t Todos) Swap(i, j int) {
t[i], t[j] = t[j], t[i]
}
func (t Todos) Less(i, j int) bool {
return t[i].ID > t[j].ID
}
func GetTodoListHandler(w http.ResponseWriter, r *http.Request) {
list := make(Todos, 0)
for _, todo := range todoMap {
list = append(list, todo)
}
sort.Sort(list)
rd.JSON(w, http.StatusOK, list) // ID로 정렬하여 전체 목록 반환
}
func PostTodoHandler(w http.ResponseWriter, r *http.Request) {
var todo Todo
err := json.NewDecoder(r.Body).Decode(&todo)
if err != nil {
log.Fatal(err)
w.WriteHeader(http.StatusBadRequest)
return
}
lastID++ // 새로운 ID로 등록하고 만든 Todo 반환
todo.ID = lastID
todoMap[lastID] = todo
rd.JSON(w, http.StatusCreated, todo)
}
type Success struct {
Success bool `json:"success"`
}
func RemoveTodoHandler(w http.ResponseWriter, r *http.Request) {
vars := mux.Vars(r) // ID에 해당하는 할 일 삭제
id, _ := strconv.Atoi(vars["id"])
if _, ok := todoMap[id]; ok {
delete(todoMap, id)
rd.JSON(w, http.StatusOK, Success{true})
} else {
rd.JSON(w, http.StatusNotFound, Success{false})
}
}
func UpdateTodoHandler(w http.ResponseWriter, r *http.Request) {
var newTodo Todo // ID에 해당하는 할 일 수정
err := json.NewDecoder(r.Body).Decode(&newTodo)
if err != nil {
log.Fatal(err)
w.WriteHeader(http.StatusBadRequest)
return
}
vars := mux.Vars(r)
id, _ := strconv.Atoi(vars["id"])
if todo, ok := todoMap[id]; ok {
todo.Name = newTodo.Name
todo.Completed = newTodo.Completed
rd.JSON(w, http.StatusOK, Success{true})
} else {
rd.JSON(w, http.StatusBadRequest, Success{false})
}
}
func main() {
m := MakeWebHandler() // 기본 핸들러 (핸들러들이 등록된 mux가 반환됨)
n := negroni.Classic() // negroni 기본 핸들러
n.UseHandler(m) // negroni 기본 핸들러로 만든 핸들러 MakeWebHandler 을 감싼다.
// HTTP 요청 수신 시 negroni에서 제공하는 부가 기능 핸들러들을 수행하고 난 뒤, MakeWebHandler()를 수행한다.
log.Println("Started App")
err := http.ListenAndServe(":3000", n) // negroni 기본 핸들러가 동작함
if err != nil {
panic(err)
}
}
좋은 설계: 상호 결합도(coupling)가 낮고 응집도(cohesion)가 높은 설계를 말한다. 반대로 상호 결합도가 높다는 것은 모듈이 서로 강하게 결합되어 있어서 떼어 낼 수 없다는 의미이다. 한편 응집도가 낮다는 것은 하나의 모듈이 스스로 자립하지 못한다는 의미로, 다른 모듈에 의존적인 관계를 가지는 경우이다.
책임이 두 가지가 되므로, 이후 마케팅 보고서라는 객체가 생겨도 회계 보고서의 SendReport()를 사용할 수 없다.
이를 개선하기 위해서 FinanceReport는 Report 인터페이스를 구현하고, ReportSender는 Report 인터페이스를 이용하는 관계를 형성하면 된다.
type Report interface { // Report() 메서드를 포함하는 Report 인터페이스
Report() string
}
type FinanceReport Struct { // 경제 보고설르 담당하는 FinanceReport
report sting
}
func (r *FinanceReport) Report() sting { // Report 인터페이스를 구현
}
type ReportSender struct { // 보고서 전송을 담당
}
func (s *ReportSender) SendReport(report Report) {
// Report 인터페이스 객체를 인수로 받음
}
개방-폐쇄 원칙(open-closed principle, OCP)
확장에는 열려 있고, 변경에는 닫혀 있어야 한다. (프로그램에 기능을 추가할 때 기존 코드의 변경을 최소화 해야 한다)
→ 상호 결합도를 줄여 새 기능을 추가할 때 쉽게 할 수 있고, 기존 구현을 변경하지 않아도 된다.
아래는 나쁜 사례로, 전송 방식을 추가할 때 새로운 case를 만들어 구현을 추가한다. (기존 SendReport() 함수 구현을 변경하게 된다.)
func SendReport(r *Report, method SendType, receiver string) {
switch method {
case Email:
// 이메일 전송
case Fax:
// Fax 전송
case PDF:
// PDF 파일 생성
case Printer:
// 프린팅
..
}
}
이를 개선하기 위해서 ReportSender 인터페이스를 생성하고, 각 방식이 이 인터페이스를 구현하도록 한다.
type ReportSender interface {
Send(r *Report)
}
type EmailSender sturct {
}
func (e *EmailSender) Send(r *Report) {
// 이메일 전송
}
type FaxSender sturct {
}
func (f *FaxSender ) Send(r *Report) {
// F ax 전송
}
리스코프 치환 원칙(liskov substitution principle, LSP)
q(x T)를 타입 T의 객체 x에 대해 증명(동작)할 수 있는 속성이라 하자. 그렇다면 S가 T의 하위 타입이라면 q(y S)는 타입 S의 객체 y에 대해 증명(동작)할 수 있어야 한다. (상위 타입을 인수로 받아 동작하는 함수는 하위 타입의 인수에도 동작해야 한다)
→ 예상치 못한 동작을 예방할 수 있다. (리스코프 치환 원칙이 지켜지지 않으면 함수의 동작을 예측하기 어렵다)
아래는 LSP에 위반 사례로, Go에서 상속이 있다는 가정으로 생각해보면 동일한 동작을 예상하는 FillScreenWidth 에서 다른 동작이 일어나는 오류가 발생한다.
class Rectangle { // 사각형
width int
height int
setWidth(w int) { width = w }
setHeight(h int) { Height = h }
}
class Square extends Rectangle { // 정사각형 (사각형을 상속)
@override
setWidth(w int) { width = w; height = w; }
@override
setHeight(h int) { width = h; height = h; }
}
// 화면 가로 크기에 맞게 이미지의 가로 크기 늘립니다. -> Square가 들어오면? 세로도 늘어난다.
func FillScreenWidth(screenSize Rectangle, imageSize *Rrectangle) {
if imageSize.width < screenSize.width {
imageSize.setWidth(screenSize.width)
}
}
Go에서는 상속이 없기 때문에 이러한 동작이 일어나지 않는다.
다만 Go에서도 인터페이스를 사용하면 상위 개체(인터페이스), 하위 개체(구현한 객체)의 관계가 생기기 때문에, 인터페이스를 인수로 받는 함수는 모든 하위 개체에서 동작이 되어야 하는 원칙이 지켜져야 한다. 그래서 인터페이스 타입 변환 같은 다이나믹 캐스팅(인터페이스 타입을 구체화된 객체로 바꾸는 것)을 하지 않는 것이 좋다.
인터페이스 분리 원칙(interface segregation principle, ISP)
클라이언트(인터페이스의 이용)는 자신이 이용하지 않는 메서드에 의존하지 않아야 한다.
→ 인터페이스를 분리하면 불필요한 메서드들과 의존 관계가 끊어져 더 가볍게 인터페이스를이용할 수 있다.
아래는 나쁜 사례로, SendReport()는 Report 인터페이스가 포함한 4개 메서드 중에 Report()메서드만 사용한다. (인터페이스에 불필요한 메서드가 포함되어 있다)
type Report interface {
Report() string
Pages() int
Author() string
WrittenDate() time.Time
}
func SendReport(r Report) { // 함수를 호출려면 인수는 4개의 메서를 다 구현하고 있어야 한다.
send(r.Report())
}
해결하기 위해서 인터페이스를 적절하게 분리해야 한다.
type Report interface {
Report() string
}
type WrittenInfo interface {
Pages() int
Author() string
WrittenDate() time.Time
}
func SendReport(r Report) { // 함수를 호출하는 Report는 사용하는 Report() 하나의 메서드만 구현하면 된다.
send(r.Report())
}
인터페이스를 분리해 불필요한 메서드들과 의존 관계를 끊으면 더 가볍게 인터페이스를 이용할 수 있다.
의존 관계 역전 원칙(dependency inversion principle, DIP)
구체화된 객체는 추상화된 객체와 의존 관계를 가져야 한다.
→ 구체화된 모듈이 아닌 추상 모듈에 의존함으로써 확장성이 증가한다. 상호 결합도가 낮아져서 다른 프로그램으로 이식성이 증가한다.
아래는 메일이라는 모듈과 알람이라는 모듈이 관계를 맺고 있는 코드이다. (메일이 알람을 소유하고 있다)
type Mail struct {
alarm Alarm
}
type Alarm struct {
}
func (m *Mail) OnRecv() { // OnRecv() 메서드는 메일 수신 시 호출된다.
m.alarm.Alarm() // 알람을 울린다.
}
이를 인터페이스를 통해 의존하도록 바꾼다.
package main
import "fmt"
type Event interface {
Register(EventListener)
}
type EventListener interface {
OnFire()
}
type Mail struct {
listener EventListener
}
func (m *Mail) Register(listener EventListener) { // Event 인터페이스 구현
m.listener = listener
}
func (m *Mail) OnRecv() { // 등록된 listner의 OnFire() 호출
m.listener.OnFire()
}
type Alarm struct {
}
func (a *Alarm) OnFire() { // EVentListner 인터페이스 구현
// 알람
fmt.Println("알람")
}
func main() {
var mail = &Mail{}
var listener EventListener = &Alarm{}
mail.Register(listener)
mail.OnRecv() // 알람이 울린다.
}
28장 테스트와 벤치마크
테스트 코드는 작성한 코드를 테스트 하는 코드이고, 벤치마크 코드는 코드 로직의 성능을 측정하는 코드이다.
28.1 테스트 코드
Go에서는 테스트 코드 작성과 실행을 언어에서 지원한다. 테스트 코드를 작성하면 go test 명령으로 실행할 수 있다.
Go의 테스트 코드의 작성 규약은 아래와 같다.
테스트 코드는 파일명이 _test.go로 끝나는 파일 안에 존재해야 한다.
테스트 코드를 작성하려면 import “testing”으로 testing 패키지를 가져와야 한다.
테스트 코드들은 함수로 묶여 있어야 하고, 함수명은 반드시 Test 로 시작해야 한다. 형태는 func TestXxxx(t *testing.T) 형태이어야 한다.
예를 들어, 아래 코드에 대한 테스트 코드 main.go를 작성해본다.
package main
import "fmt"
func square(x int) int {
return 81
}
func main() {
fmt.Printf("9*9=%d\\n", square(9))
}
동일한 위치에서 main_test.go를 만들고 아래와 같이 작성한다.
package main
import "testing"
func TestSquare(t *testing.T) {
rst := square(9)
if rst != 81 {
t.Errorf("square(9) should be 81, but returns %d", rst)
}
}
아래는 테스트 결과이다.
$ go test
PASS
ok goprojects/test28 1.010s
테스트 코드 작성 규칙을 따라 테스트 코드 파일을 _main.go 로 끝나게 맞춰줘야 테스트 코드로 인식한다. 아래는 테스트 파일을 제대로 인식하지 못한 에러이다.
$ go test
? goprojects/test28 [no test files]
테스트 코드를 추가한다.
func TestSquare2(t *testing.T) {
rst := square(3)
if rst != 9 {
t.Errorf("square(3) should be 9, but returns %d", rst)
}
}
다시 테스트를 돌려보면 테스트 코드가 실패한 것을 확인할 수 있다.
$ go test
--- FAIL: TestSquare2 (0.00s)
main_test.go:17: square(3) should be 9, but returns 81
FAIL
exit status 1
FAIL goprojects/test28 0.950s
실제 코드가 하드 코딩되어 발생한 에러로 return x*x 로 수정한다.
VS Code에서는 아래와 같이 자동으로 테스트가 가능하도록 생긴다. run package tests 를 클릭해도 된다. run package tests 는 패키지 전체의 테스트를 수행하고, run test 로 개별 테스트를 수행할 수 있다. 커맨드 라인에서는 go test -run 테스트명 으로 개별 테스트를 수행할 수 있다.
테스트 코드 작성을 간결하게 도와주는 stretchr/testify 패키지를 사용해본다.
package main
import (
"testing"
"github.com/stretchr/testify/assert"
)
func TestSquare1(t *testing.T) {
assert := assert.New(t) // 테스트 객체 생성
assert.Equal(81, square(9), " square(9) should be 81") // 테스트 함수 호출
}
func TestSquare2(t *testing.T) {
assert := assert.New(t)
assert.Equal(9, square(3), " square(3) should be 9")
}
go get 으로 패키지를 설치하고 테스트를 수행해본다.
$ go test
# goprojects/test28
main_test.go:6:2: no required module provides package github.com/stretchr/testify/assert; to add it:
go get github.com/stretchr/testify/assert
FAIL goprojects/test28 [setup failed]
$ go get github.com/stretchr/testify/assert
go: added github.com/davecgh/go-spew v1.1.1
go: added github.com/pmezard/go-difflib v1.0.0
go: added github.com/stretchr/testify v1.8.4
go: added gopkg.in/yaml.v3 v3.0.1
$ go test
PASS
ok goprojects/test28 1.201s
임의로 테스트 코드에 에러를 발생시켜 보면 테스트 코드의 결과가 상세하게 바뀐 것을 알 수 있다.
$ go test
--- FAIL: TestSquare1 (0.00s)
main_test.go:11:
Error Trace: C:/../projects/goprojects/test28/main_test.go:11
Error: Not equal:
expected: 8
actual : 81
Test: TestSquare1
Messages: square(9) should be 81
FAIL
exit status 1
FAIL goprojects/test28 0.924s
Equal() 메서드 외에도 NotEqual(), Nil(), NotNil() 등의 메서드를 제공한다.
stretchr/testify 패키지에서 mock, suite 패키지를 제공하고 있다.
mock 패키지: 모듈의 행동을 가장하는 목업(mockup) 객체를 제공한다. 예를 들어, 온라인 기능 테스트를 할 때 하위 영역인 네트워크 객체를 가장하는 목업 객체를 만들 때 유용하다. suite 패키지: 테스트 준비 작업이나 테스트 종료 후 처리 작업을 도와주는 패키지이다. 예를 들어, 텍스트에 특정 파일이 있어야 하는 경우, 임시 파일을 생성하고, 테스트 종료 후 삭제해주는 작업을 만들 때 유용하다.
28.2 테스트 주도 개발
테스트의 중요성이 커짐에 따라 코드 작성 이전에 테스트 코드를 작성하는 테스트 주도 개발(Test Driven Development, TDD) 방식을 소개한다.
테스트는 크게 블랙박스 테스트와 화이트 박스 테스트로 구분할 수 있다.
블랙박스 테스트는 제품 내부를 오픈하지 않은 상태에서 진행되는 테스트이다. 사용자 입장의 테스트라고 해서 사용성 테스트(usability test)라고 하기도 한다. 프로그램 코드에 대한 검증이 아니라, 프로그램을 실행한 상태에서 동작을 검사하는 방식이다. 보통 전문 테스트, QA 직군에서 담당한다.
화이트박스 테스트는 내부 코드를 직접 검증하는 방식이다. 유닛 테스트(unit test, 단위 테스트)라고 부른다. 프로그래머가 직접 테스트 코드를 작성해서 내부 테스트를 검사하는 방식이다.
전통적인 화이트박스 테스트는 코드 작성 → 테스트 → 버그 발견 → 코드 수정 로 이뤄진다.
이러한 방식은 코드 작성 후 테스트 코드를 작성하다 보니 메인 시나리오에 의존해 테스트를 하여 예외 상황이나 경계 체크(boundary check)가 무시되기 쉽다. 또한 테스트 통과를 목적으로 하는 형식적인 테스트 코드가 될 수 있다.
테스트 주도 개발(TDD)이 대안이 될 수 있다. 테스트 주도 개발은 테스트 코드 작성 시기를 코드 작성 이전으로 옮긴 방식이다. 테스트 작성 → 테스트 실패 → 코드 작성 → 테스트 성공→ 개선 을 반복하여 코드를 테스트를 성공시키고 리팩터링(refactoring)하여 완성하는 방식이다.
28.3 벤치마크 코드
Go의 testing 패키지는 테스트 코드 외에 코드의 성능을 검사하는 벤치마크 기능을 지원한다.
Go의 벤치마크 코드의 작성 규약은 아래와 같다.
벤치마크 코드는 파일명이 _test.go로 끝나는 파일 안에 존재해야 한다.
벤치마크 코드를 작성하려면 import “testing”으로 testing 패키지를 가져와야 한다.
벤치마크 코드들은 함수로 묶여 있어야 하고, 함수명은 반드시 Benchmark로 시작해야 한다. 형태는 func BenchmarkXxxx(b *testing.B) 형태이어야 한다.
벤치마크 코드는 go test -bench . 로 실행할 수 있다.
29장 Go 언어로 만드는 웹 서버
HTTP 프로토콜을 사용하여 요청에 응답하는 서버를 웹 서버 혹은 HTTP 서버라고 한다. Go에서는 net/http 패키지를 제공한다.
Go에서 웹서버를 만들려면 핸들러 등록과 웹서버 시작이라는 두 단계를 거친다.
핸들러란 각 HTTP 요청이 수신됐을 때 HTTP 요청 URL 경로에 대응해 처리하는 함수 또는 객체라고 보면 된다.
핸들러는 HandleFunc() 함수로 등록할 수 있고, ListenAndServer() 함수로 웹 서버를 시작한다.
package main
import (
"fmt"
"net/http"
)
func main() {
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
fmt.Fprint(w, "Hello world!") // 핸들러 등록
})
http.HandleFunc("/bar", func(w http.ResponseWriter, r *http.Request) {
fmt.Fprint(w, "Bar pasge!") // /bar에 대한 핸들러 등록
})
http.ListenAndServe(":3000", nil) // 웹서버 시작
}
HandleFunction()의 핸들러 함수는 두 인수를 가지는데, http.Request 에는 클라이언트에서 보낸 메서드, 헤더, 바디와 같은 HTTP 요청 정보를 가지고, http.ResponseWriter 인수는 이후 Fprint()의 출력 스트림으로 지정된다. http.ResponseWriter 타입에 값을 쓰면 HTTP 응답으로 전송된다.
ListenAndServe() 는 두가지 인수를 가지는데, 첫번째 인수는 HTTP 요청을 수신하는 주소를 입력하고, 두번째 인수에는 핸들러 인스턴스를 넣어준다. 이 값이 nil을 넣어주면 DefaultServeMux를 사용하는데, DefaultServeMux는 http.HandleFunc() 함수로 등록된 핸들러들을 사용한다.
http를 인스턴스를 명시적으로 만들지 않고, 바로 사용한다? http.ResponseWriter와 http.Request는 언제 만들어지는 걸까? http.HandleFunc에 함수 리터럴인 부분은 실제로 언제 사용될지 모르는 부분이다. http.ListenAndServer()로 웹서버가 시작되고, 실제로 이 핸들러가 호출될 때, http.ResponseWriter와 http.Request가 전달된다.
DefaultServeMux를 사용하면 http.HandleFunc()을 이용해서 등록한 핸들러를 사용하기 때문에 다양한 기능을 추가하기 어렵다.
앞의 기본 예제를 ServeMux 인스턴스를 생성해 사용할 수 있다.
package main
import (
"fmt"
"net/http"
)
type fooHandler struct{}
func (f *fooHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
fmt.Fprint(w, "foo pasge!") // 핸들러로 사용되는 구조체는 ServeHTTP를 구현해야 한다
}
func main() {
mux := http.NewServeMux()
mux.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
fmt.Fprint(w, "Hello world!") // 핸들러 등록
})
mux.HandleFunc("/bar", func(w http.ResponseWriter, r *http.Request) {
fmt.Fprint(w, "Bar pasge!") // /bar에 대한 핸들러 등록
})
mux.Handle("/foo", &fooHandler{}) // handler 구조체를 선언해서 mxu.Handle()에 추가하는 방법
http.ListenAndServe(":3000", mux) // 웹서버 시작
}
Mux: multiplexer(멀티플렉서)의 약자로 여러 입력 중 하나를 선택해서 반환하는 디지털 장치를 말한다. 여기서는 각 URL에 대한 핸들러를 등록한 다음, HTTP 요청이 왔을 때 URL에 해당하는 핸들러를 선택해서 실행하는 방식이다. 이러한 방식을 라우터(router)라고 말하기도 한다.
과거의 웹 서버가 서버에 위치한 HTML을 전달하는 목적이었다면, 현재의 웹 서버에는 아래와 같은 변화가 있다.
Server Rendering → Client Rendering
Server Rendering은 요청에 대해 서버에서 로직을 수행 결과로 HTML를 만들어 응답하는 구조이라면, Client Rendering은 요청에 대해 서버가 HTML의 틀(템플릿) 제공하고, 클라이언트에서 렌더링을 할 때 템플릿을 동적으로 데이터를 채워나가는 방식이다. 동적인 요청에 대한 결과를 JSON이라는 데이터 형태로 받는다.
Frontend와 Backend의 혼합 → Frontend와 Backend의 역할의 분할
Frontend가 Client Rendering을 담당하고, Backend에서는 로직을 수행하고 데이터의 전달을 담당한다.
이 과정에서 중요한 역할을 하는 JSON 데이터를 처리하는 방식을 살펴본다.
JSON(JavaScript Object Notation) 데이터를 전송하기 위해서 encoding/json 패키지를 사용한다. 이 패키지를 사용해 구조체를 JSON 데이터로 변환(marshal, encode)하고, 다시 JSON 데이터를 구조체로 변환(unmarshal, decode)할 수 있다.
package main
import (
"encoding/json"
"fmt"
"net/http"
)
type Student struct {
Name string
Age int
Score int
}
func MakeWebHandler() http.Handler { // 핸들러 인스턴스를 생성하는 함수
mux := http.NewServeMux()
mux.HandleFunc("/student", StudentHandler)
return mux
}
func StudentHandler(w http.ResponseWriter, r *http.Request) {
var student = Student{"aaa", 16, 87}
data, _ := json.Marshal(student) // Student 객체를 []byte로 변환
w.Header().Add("content-type", "application/json") // 헤더에 JSON 포맷임을 표시
w.WriteHeader(http.StatusOK)
fmt.Fprint(w, string(data))
}
func main() {
http.ListenAndServe(":3000", MakeWebHandler())
}
테스트 코드를 통해서 JSON 데이터를 받아 객체로 변환해본다 처리해 본다.
package main
import (
"encoding/json"
"net/http"
"net/http/httptest"
"testing"
"github.com/stretchr/testify/assert"
)
func TestJsonHalander(t *testing.T) {
assert := assert.New(t)
res := httptest.NewRecorder() // 테스트 response 레코더를 만든다.
req := httptest.NewRequest("GET", "/student", nil) // /student 경로 테스트
mux := MakeWebHandler()
mux.ServeHTTP(res, req)
assert.Equal(http.StatusOK, res.Code) // http 상태 코드 확인
student := new(Student)
err := json.NewDecoder(res.Body).Decode(student) // 결과 변환(res.Body의 결과를 decode해서 student 객체에 담는다)
// 결과 확인
assert.Nil(err)
assert.Equal("aaa", student.Name)
assert.Equal(16, student.Age)
assert.Equal(87, student.Score)
}
RESTful API는 서버에서 어떠한 리소스를 제공할 때 이 리소스에 접근하는 API의 설계 방식이다. REST에서는 HTTP 프로토콜을 사용하고, 리소스를 URI(uniform resource identifier)로 대응시키고, 지정된 URI에 대해서 HTTP 메서드를 대칭해 해당 리소스에 대한 CRUD를 관리한다.
REST에서는 URL과 HTTP 메서드로 데이터와 동작을 표현한다.
GET <Https://somesite.com/students/3>
URL과 메서드를 보면 이 요청이 3번 학생 데이터를 가져오는 요청이라는 것을 유추할 수 있다.
이때 메서드는 HTTP 메서드를 의미하는데, 아래와 같은 메서드를 지원한다. 이러한 메서드를 바탕으로 URL로 전달한 자원에 대한 동작을 정의한다. 이렇게 URL 만으로 어떤 요청인지 알 수 있기 때문에 RESTful API의 특징을 자기표현적인 URL이라고 한다.
메서드 URL 동작
GET
/students
전체 학생 데이터 반환
GET
/students/3
id에 해당하는 학생 데이터 반환
POST
/students
새로운 학생 등록
PUT
/students/id
id에 해당하는 학생 데이터 변경
DELETE
/students/id
id에 해당하는 학생 데이터 삭제
여기서는 아래의 단계로 RESTful API에 맞는 웹서버를 구현한다.
gorilla/mux 와 같은 RESTful API 웹 서버 제작을 도와주는 패키지를 설치한다.
RESTful API에 맞춰서 웹 핸들러 함수를 만들어 준다.
RESTful API를 테스트하는 테스트 코들르 만든다.
웹 브라우저로 데이터를 조회한다.
이 예제에서는 학생(Student) 구조체를 정의하고, 이 리소스를 위의 표와 같은 동작을 하는 REST API로 구현해본다.
package main
import (
"encoding/json"
"net/http"
"sort"
"strconv"
"github.com/gorilla/mux"
)
type Student struct {
Id int
Name string
Age int
Score int
}
var students map[int]Student // 학생 목록을 저장하는 맵
var lastId int // map id로 사용
// gorilla/mux 패키지를 이용해 웹 핸들러를 만들고, 임시 학생 데이터 두개 생성 저장
func MakeWebHandler() http.Handler {
mux := mux.NewRouter() // gorilla/mux를 만든다.
// /students 요청을 받으면 GetStudentListHandler() 함수가 호출되도록 하고,
// Methods() 메서들르 통해 GET 메서드 요청을 받을 때만 핸들러가 동작하도록 한다.
mux.HandleFunc("/students", GetStudentListHandler).Methods("GET") // 학생 리스트
// <- 여기에 새로운 핸들러 등록 ->
mux.HandleFunc("/students/{id:[0-9]+}", GetStudentHandler).Methods("GET") // id 학생 정보
mux.HandleFunc("/students", PostStudentHandler).Methods("POST") // 학생 추가
mux.HandleFunc("/students/{id:[0-9]+}", DeleteStudentHandler).Methods("DELETE") // 학생 삭제
// 임시데이터 생성
students = make(map[int]Student)
students[1] = Student{1, "aaa", 16, 87}
students[2] = Student{2, "bbb", 17, 89}
lastId = 2
return mux
}
// Id 로 정렬하는 인터페이스 구현
// Len(), Less(), Swap() 메서드를 구현해 sort.Interface를 사용할 수 있게함
// sort.Sort(Students(s)) 형태로 사용
type Students []Student
func (s Students) Len() int {
return len(s)
}
func (s Students) Swap(i, j int) {
s[i], s[j] = s[j], s[i]
}
func (s Students) Less(i, j int) bool {
return s[i].Id < s[j].Id
}
// 학생 정보를 가져와 JSON 포맷으로 변경하는 핸들러
func GetStudentListHandler(w http.ResponseWriter, r *http.Request) {
list := make(Students, 0)
for _, student := range students {
list = append(list, student)
}
sort.Sort(list) // 학생 목록을 Id로 정렬
w.Header().Set("Content-Type", "application/json")
w.WriteHeader(http.StatusOK) // 책에서는 윗라인과 순서가 바뀜. w.Header().Set() 후에 w.WriteHeader() 해야한다.
json.NewEncoder(w).Encode(list) // JSON 포맷으로 변경해서 결과를 쓴다.
}
// id에 해당하는 학생을 가져와 반환하는 핸들러
func GetStudentHandler(w http.ResponseWriter, r *http.Request) {
vars := mux.Vars(r) // mux에 요청으로 들어온 URL에서 인수를 가져온다.
id, _ := strconv.Atoi(vars["id"]) // 경로가 /students/{id:[0-9]+} 이므로, gorillar/mux에서 자동으로 id값을 내부 맵에 저장한다. vars["id"]로 id 값 가져온다.
student, ok := students[id] // student 맵에서 데이터가 있는지 확인한다.
if !ok {
w.WriteHeader(http.StatusNotFound)
return
}
w.Header().Set("Content-Type", "application/json")
w.WriteHeader(http.StatusOK)
json.NewEncoder(w).Encode(student)
}
// POST 요청이 오면 학생을 추가하는 핸들러
func PostStudentHandler(w http.ResponseWriter, r *http.Request) {
var student Student
err := json.NewDecoder(r.Body).Decode(&student)
if err != nil {
w.WriteHeader(http.StatusBadRequest)
return
}
lastId++
student.Id = lastId
students[lastId] = student
w.WriteHeader(http.StatusCreated)
}
// DELETE 요청이 오면 학생을 삭제하는 핸들러
func DeleteStudentHandler(w http.ResponseWriter, r *http.Request) {
vars := mux.Vars(r)
id, _ := strconv.Atoi(vars["id"])
_, ok := students[id]
if !ok {
w.WriteHeader(http.StatusNotFound)
return
}
delete(students, id)
w.WriteHeader(http.StatusOK)
}
func main() {
http.ListenAndServe(":3000", MakeWebHandler())
}
참고로 노출하지 않은 HTTP 메서드로 접근하면 아래와 같은 에러가 발생한다. 405: Method Not Allowed 이다.
--- FAIL: TestJsonHandler3 (0.00s)
main_test.go:68:
Error Trace: C:/Users/montauk/Desktop/projects/goprojects/rest30/main_test.go:68
Error: Not equal:
expected: 201
actual : 405
Test: TestJsonHandler3
이렇게하면 open data.txt: no such file or directory으로 종료한다.
fmt 패키지의 Errorf() 함수로 err을 반환하면 원하는 에러 메시지를 만들어 전달할 수 있다. 또는 errors 패키지의 New()함수를 이용해서 error를 생성할 수도 있다.
import "errors"
errors.New("에러 메시지")
error 타입은 인터페이스로 문자열을 반환하는 Error() 메서드로 구성되어 있다. 즉 어떤 타입이든 문자열을 반환하는 Error()메서드를 포함하고 있다면 에러로 사용할 수 있다.
type error interface {
Error() sting
}
회원 가입에서 패스워드 길이를 체크하는 예제를 살펴본다.
package main
import (
"fmt"
)
type PasswordError struct { // 에러 구조체 선언
Len int
RequireLen int
}
func (err PasswordError) Error() string {
return "암호 길이가 짧습니다."
}
func RegisterAccount(name, password string) error {
if len(password) < 8 {
return PasswordError{len(password), 8} // 에러 반환, 암호 길이가 짧을 때 PasswordError 구조체 정보 반환
}
return nil
}
func main() {
err := RegisterAccount("myaccnt", "mypw")
if err != nil { // 에러 확인
if errInfo, ok := err.(PasswordError); ok { // 인터페이스 변환, 인터페이스 변환 성공 여부 검사(ok)->다양한 에러 타입에 대응
fmt.Printf("%v Len:%d RequireLen:%d\\n",
errInfo, errInfo.Len, errInfo.RequireLen)
}
} else {
fmt.Println("회원 가입 했습니다.")
}
}
한편 패닉(panic)은 프로그램을 정상 진행시키기 어려운 상황을 만났을 때 프로그램 흐름을 중지시키는 기능이다.
지금까지 error 인터페이스를 사용해 에러를 처리해 사용자에게 에러의 이유를 알려주는 것이지만(사용자 관점), 이와는 다르게 panic()은 문제 발생 시점 빠르게 프로그램을 종료시켜서 빠르게 문제 발생 시점을 알게하는 방식이다(개발자 관점).
panic() 내장 함수를 호출하고 인수로 에러 메시지를 입려갛면 프로그램을 즉시 종료하고 에러 메시지를 추력하고, 함수 호출 순서를 나타내는 콜 스택(call stack)을 표시한다.
package main
import (
"os"
)
const filename string = "data.txt"
func main() {
file, err := os.Open(filename)
if err != nil {
panic("파일을 읽을 수 없습니다")
}
defer file.Close()
}
앞선 예제를 panic()으로 처리하면 아래와 같이 call stack이 떨어진다.
panic: 파일을 읽을 수 없습니다
goroutine 1 [running]:
main.main()
/tmp/sandbox3015253680/prog.go:12 +0x85
Program exited.
콜 스택이란 panic 이 발생한 마지막 함수 위치부터 역순으로 호출 순서를 표시한다.
프로그램을 개발하는 시점에는 문제점을 파악하고 수정하는 것이 중요하지만, 사용자에게 인도가 된 이후에는 문제가 발생하더라도 프로그램이 종료되는 대신 에러 메시지를 표시하고 복구를 시도하는 것이 나을 수 있다.
panic은 호출 순서를 거슬러 올라가며 전파되는데, main() → f() → g() → h() 순서로 호출되었을 때, h()에서 패닉이 발생하면 호출 순서를 거꾸로 올라가면서 g() → f() → main() 으로 전달된다. 이때, recover()를 만나면 패닉을 복구할 수 있다.
다만 recover() 또한 제한적으로 사용하는 것이 좋다. 복구가 되더라도 프로그램 상태가 불안정한 상태(데이터가 일부가 쓰여지거나 하면서 데이터가 비정상 적으로 저장될 수 있음)로 남는 것을 주의해야 한다.
24. 고루틴과 동시성 프로그래밍
고루틴(goroutine)은 경량 스레드로 함수나 명령을 동시에 실행할 때 사용한다. 프로그램 시작점인 mian() 또한 고루틴에 의해 실행된다.
보통 단일 Core에서 멀티 스레드 프로세스를 지원하기 위해 시분할로 다수의 스레드를 처리하지만 이 과정에서 컨텍스트 스위치(context switch: 현재의 상태_context를 보관하고 새로운 상태를 복원) 비용이 발생한다.
Go에서는 CPU 코어 마다 OS 스레드를 하나만 할당해서 사용하기 때문에 컨텍스트 스위칭 비용이 발생하지 않는다. 실제로 하나의 OS 스레드에 하나의 고루틴이 실행된다.
컨텍스트 스위칭은 CPU 코어가 스레드를 변경할 때 발생하는데, 고루틴을 이용하면 코어와 스레드는 변경되지 않고 오직 고루틴만 옮겨 다니기 때문에(코어가 스레드를 변경하지 않음) 컨텍스트 스위칭 비용이 발생하지 않는다.
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup // wiatGroup 객체
func SumAtoB(I, a, b int) {
sum := 0
for i := a; i <= b; i++ {
sum += i
}
fmt.Printf("%d번째: %d ~ %d 합계는 %d 이다\\n", I, a, b, sum)
wg.Done() // 작업 1개 완료를 의미
}
func main() {
wg.Add(10) // 총 작업 수 설정
for i := 0; i < 10; i++ {
go SumAtoB(i, 1, 100000)
}
wg.Wait() // 모든 작업의 완료 대기
}
여기서는 앞서 다루지 않은 프로그램 그램 실행 시점 실행 인수를 전달하는 방법과 파일에서 한 줄 씩 읽어서 처리하는 방식을 추가로 다루고 있다. 한편 검색해야 하는 파일이 여러 개일 때, 파일을 하나 씩 검색하는 것보다 빠르게 실행하기 위해서, 각 파일에 대한 검색을 고루틴으로 적용한다.
먼저 Go에서는 실행 인수를 os.Args 변수를 이용해서 가져올 수 있다.
os.Args // 실행 인수 개수
os.Args[1] // 실행 인수 가져오기
그리고 파일에서 단어를 찾기 위해서 파일을 열고, bufio 패키지의 NewScanner()함수를 이용해 스캐너를 만들고 파일 내용을 한 라인씩 읽어 올 수 있다.
scanner := bufio.NewScanner(file) // 스캐너를 생성해서 한 줄씩 읽기
for scanner.Scan() {
fmt.Println(scanner.Text())
}
실제 scanner.Text()에서 파일이 있는지 여부는 한 라인에 대해서 strings.Contains(라인, 찾는단어)로 확인한다.
다만 실행 인수에 단어를 찾을 다수의 파일이 들어온다면, 다수 파일에서 단어 검색을 처리하기 위해서 고루틴을 활용해 시간을 단축할 수 있다.
다만 슬라이스를 초기화 하지 않으면 길이가 0인 슬라이스가 만들어 지는 것이기 때문에 임의로 인덱스를 접근하면 패닉이 발생한다.
package main
func main() {
var slice []int
slice[1] = 10
}
// 에러
panic: runtime error: index out of range [1] with length 0
goroutine 1 [running]:
main.main()
/tmp/sandbox4095475310/prog.go:6 +0x14
슬라이스의 초기화와 요소 추가, 삭제
var slice1 []int{1,2,3} // 대괄호 안에 길이가 없다, {} 안에 요소값을 넣어서 초기화 할수 있다.
var array [...]int{1,2,3} // 고정길이 3인 배열이다. 슬라이스와 다르다.
var slice = make([]int,3) // 슬라이스는 make()를 통해서 초기화 할 수 있다.
// 슬라이스는 요소 추가를 위해 append()를 사용할 수 있다.
slice1 = append(slice1, 4)
// 슬라이스 요소 삭제를 위해 append()를 활용할 수 있다.
slice1 = append(slice[:idx], slice[idx+1:]...)
// 슬라이스의 중간에 요소 추가하기 위해 append()를 활용할 수 있다.
slice1 = append(slice[:idx], append([]int{100}, slice[idx:]...)...)
// 슬라이스 정렬
sort.Ints(slice1) // float64는 sort.Float64s() 사용
… 사용이 복잡하다 → 예시 확인
append()함수는 append(slice, 3,4,5)와 같이 첫 번째 인자로 주어진 slice에 여러 값을 추가할 수 있다. 아래의 예시에서도 append(slice, 요소,요소)와 같이 사용하기 위해, 여러 요소라는 의미로 slice…(슬라이스 전체)를 사용한 것이라고 이해하자.
package main
import "fmt"
func main() {
var slice1 = []int{1, 2, 3}
fmt.Println(slice1) //[1 2 3]
//슬라이스 요소 추가
slice1 = append(slice1, 4)
fmt.Println(slice1) //[1 2 3 4]
//슬라이스 요소 삭제
idx := 1
//slice1 = append(slice1[:idx], slice1[idx+1:]) //[에러] ./prog.go:13:38: cannot use slice1[idx + 1:] (value of type []int) as int value in argument to append
slice1 = append(slice1[:idx], slice1[idx+1:]...) // 배열이나 슬라이스 뒤에 ...를 하면 모든 요소값을 넣어준 것과 같게 됨
fmt.Println(slice1) //[1 2 3 4]
//슬라이스의 중간에 요소 추가
slice1 = append(slice1[:idx], append([]int{100}, slice1[idx:]...)...)
fmt.Println(slice1) // [1 100 3 4]
}
예시에서는 슬라이싱(배열의 일부를 집어내는 기능)을 사용했다. 슬라이싱의 결과는 슬라이스이다.
array[startIdx:endIndx]
슬라이스는 배열의 일부를 나타내는 타입으로 포인터, len, cap 필드로 구성되어 있다. 포인터로 배열의 중간을 가리키고, len으로 포인터부터 일정 개수를, 그리고 cap은 포인터가 가리키는 배열이 할당된 크기(안전하게 사용할 수 있는 남은 배열 개수)를 나타낸다.
array := [5]int{1,2,3,4,5}
slice := array[1:2] // 이때 포인터는 array[1], len은 1, cap은 4가 된다.
slice1 := []int{1,2,3,4,5}
slice2 := slice1[:3] // 처음부터 슬라이싱
slice3 := slice1[2:] // 끝까지 슬라이싱
결과
package main
import "fmt"
func main() {
slice1 := []int{1, 2, 3, 4, 5}
slice2 := slice1[:3] // 처음부터 슬라이싱
slice3 := slice1[2:] // 끝까지 슬라이싱
fmt.Println(slice1)
fmt.Println(slice2) // [1 2 3], 시작 인덱스 부터 슬라이싱
fmt.Println(slice3) // [3 4 5], 끝 인덱스-1 까지 슬라이싱
}
슬라이스 동작 원리
슬라이스의 내부 정의는 아래와 같다. 슬라이스가 실제 배열을 가리키는 포인터를 가지고 있어서, 쉽게 크기가 다른 배열을 가리키도록 변경할 수 있고, 슬라이스 변수 대입 시 배열에 비해서 사용되는 메모리나 속도에 이점이 있다.
type SliceHeader struct {
Data uintptr // 실제 배열을 가리키는 포인터
Len int // 요소 개수
Cap int // 실제 배열의 길이
}
슬라이스와 배열 동작은 아래와 같은 차이가 있다.
package main
import "fmt"
// 배열은 모든 값이 복사되기 때문에, 함수내의 배열은 다른 배열이다.
func changeArray(array2 [5]int) {
array2[2] = 500
}
// slice값이 복사되면 구조체의 각 필드값이 복사되어서 포인터의 메모리 주소값도 복사되고, 실제로 slice2는 복사되어도 같은 배열 데이터를 가리키게 된다.
func changeSlice(slice2 []int) {
slice2[2] = 500
}
func main() {
array := [5]int{1, 2, 3, 4, 5}
slice := []int{1, 2, 3, 4, 5}
changeArray(array)
changeSlice(slice)
fmt.Println(array) //[1 2 3 4 5]
fmt.Println(slice) //[1 2 500 4 5]
}
19. 메서드
메서드(method)는 함수의 일종으로, 구조체 밖에서 메서드를 지정할 수 있다. 이때 특정 구조체의 메소드라는 것을 명시하기 위 리시버(reciver)를 func 키워드와 함수 이름 사이에 중괄호로 명시한다.
리시버로 모든 로컬 타입(해당 패키지 안에서 type 키워드로 선언된 타입)이 사용 가능하다. 기본 내장 타입도 사용자 정의 타입으로 별칭 타입으로 변환하여 메서드를 선언할 수 있다.
메서드는 왜 필요한가?
메서드는 리서버에 속한다. 메서드를 사용해서 데이터와 기능을 묶을 수 있게 된다.
아래의 예시와 같이 함수에 포인터 변수를 전달해서 동일한 목적을 수행할 수도 있는데, 왜 메서드를 이용할까?
package main
import "fmt"
type account struct {
balance int
}
func withdrawFunc(a *account, amount int) { // 일반 함수 표현
a.balance -= amount
}
func (a *account) withdrawMethod(amount int) { // 메서드 표현
a.balance -= amount
}
func main() {
a := &account{100} // balance가 100인 account 포인터 변수 생성
withdrawFunc(a, 30) // 함수 형태 호출
fmt.Println(a) // 70
a.withdrawMethod(30) // 메서드 형태 호출
fmt.Println(a) // 40
}
예를 들어, ‘성적 입력 프로그램’을 만들 때, Student라는 구조체가 있다고 하면, 이 구조체의 필드로 이름, 반, 번호, 성적 등의 데이터가 있다. 메서드는 성적 입력, 반 배정 등의 Student 구조체의 기능을 나타낸다.
좋은 프로그래밍이라면 결합도(coupling, 객체간의 의존 관계)를 낮추고, 응집도(cohesion, 모듈 내 요소들의 상호 관련성)을 높여햐 한다. 메서드는 데이터와 관련된 기능을 묶기 때문에 코드 응집도를 높이는 중요한 역할을 한다. 응집도가 낮으면 새로운 기능을 추가할 때 흩어진 모든 부분을 검토하고 고쳐야 하는 문제가 발생한다. 응집도가 높으면 필요한 코드만 수정하면 된다.
현대의 프로그래밍에서는 함수 호출 순서보다 객체를 만들고, 다른 객체와 상호 관계를 맺는 것이 더 중요해 졌다. 이때 객체 간 상호 관계는 메서드로 표현된다.
리시버를 값 타입 vs. 포인터 타입 메서드
포인터 타입 메서드를 호출하면 포인터가 가리키고 있는 메모리 주소 값이 복사된다(서로 같은 주소값을 가지게 됨). 반면 값 타임 메서드를 호출하면 리시버 타입의 모든 값이 복사된다(서로 다른 주소값을 가지게 됨).
포인터 타입 메서드는 메서드 내부에서 리시버의 값을 변경시킬 수 있다. → 인스턴스 중심
값 타입 메서드는 호출하는 쪽과 메서드 내부의 값은 별도 인스턴스로 독립되기 때문에 메서드 내부에서 리시버의 값을 변경시킬 수 없다. → 값 중심
20. 인터페이스
인터페이스(interface)란 구현하지 않은 메서드 집합이다. 이를 이용하면 메서드 구현을 포함한 구체화된 객체(concrete object)가 아닌 추상화된 객체로 상호작용을 할 수 있다.
→ 구체화된 타입이 아닌, 인터페이스만 가지고 메서드를 호출할 수 있어, 추후 프로그램 요구사항 변경 시 유연하게 대체할 수 있다.
→ Go에서는 인터페이스 구현 여부를 그 타입이 인터페이스에 해당하는 메서드를 가지고 있는지로 판단한다(덕 타이핑: 타입 선언 시 인터페이스 구현 여부를 명시적으로 나타낼 필요 없이 인터페이스에 정의한 메서드 포함 여부만으로 결정한다).
Keyword: 인터페이스를 구현하면 인터페이스로 메서드를 호출할 수 있다. 프로그램의 요구사항 변경에 유연하게 대처 할 수 있다.
인터페이스 선언은 아래와 같다.
type DuckInterface interface {
// 메서드 집합
Fly()
Walk(distance int) int
}
인터페이스 예시
package main
import "fmt"
type Stringer interface { // String 메서드를 가지면 뒤에 ~er 로 인터페이스명을 만든다.
String() string
}
type Student struct {
Name string
Age int
}
func (s Student) String() string { // Student의 String() 메서드가 Stringer 인터페이스를 구현함, Student 타입은 Stringer 인터페이스로 사용될 수 있다.
return fmt.Sprintf("안녕! 나는 %d살 %s라고 해", s.Age, s.Name)
}
func main() {
student := Student{"후후", 12}
var stringer Stringer
stringer = student // stringer 값으로 Student 타입 변수 student를 대입힌다. stringer는 Stringer 인터페이스이고 Stduent 타입은 String() 메서드를 포함하고 있기 때문에 stinger 값으로 stduent를 대입할 수 있다.
fmt.Printf("%s\\n", stringer.String()) // stringer 인터페이스가 가지고 있는 메서드 String()을 호출한다. stringer 값으로 Stduent 타입 ㄴtudent를 가지고 있기 때문에 student의 메서드 String()이 호출되어 반환된다.
}
→ 인터페이스 타입 변수에 인터페이스를 구현한 타입 변수를 대입할 수 있다.
→ 인터페이스 타입 변수로 메서드를 호출하면, 이를 구현한 타입의 메서드를 호출 한다.
추상화
내부 동작을 감춰서 서비스를 제공하는 쪽과 사용하는 족 모두에게 자유를 주는 방식을 추상화라고 한다. 인터페이스는 추상화를 제공하는 추상화 계증(abstration layer)이다.
이렇게 추상화 계층을 이용해 서로 결합을 귾는 것을 디커플링(decoupling)이라 말한다. 결함도는 낮출 수록 좋다.
추상화 계층을 거치면, 내부구현을 알 수 없고 오직 인터페이스(메서드의 집합)만 알 수 있다. 이것을 객체 간 관계라고 정의할 수 있다. 택배회사와 택배 이용자는 택배 전송 관계로, 은행과 은행 이용자는 입금과 인출 관계로 상호작용 한다.
→ 구체화된 타입(내부 구현이 모드 있는 타입)으로 상호작용 하는 것이 아니라 관계로 상호작용 한다.
인터페이스의 특별한 기능
포함된 인터페이스: 인터페이스가 다른 인터페이스를 포함하는 경우가 있다.
빈 인터페이스 interface{}를 인수로 받기: 어떤 값이든 받을 수 있는 함수, 메서드, 변수값을 만들 때 사용한다.
인터페이스 변수의 기본값은 유효하지 않은 메모리 주소를 나타내는 nil이다.
인터페이스를 구체화된 다른 타입으로 타입 변환하려면 a.(ConcreteType)와 같이 구체화된 타입이나 다른 인터페이스로 변환 할 수 있다.
21. 함수 고급편
21.1 가변 인수 함수
fmt.Println() 과 같이 함수의 인수가 정해져 있지 않은 경우, 즉 함수 인수 개수가 고정적이지 않은 함수를 가변 인수 함수(variadic function)이라고 한다.
이런 함수는 … 키워드를 사용해서 가변 인수를 처리하면 된다.
package main
import "fmt"
func sum(nums ...int) int { // 가변 인수 함수는 ... 키워드로 가변 인수를 받는다.
sum := 0
fmt.Printf("nums의 타입: %T\\n", nums) // nums 의 타입은 []int (슬라이스) 이다.
for _, v := range nums {
sum += v
}
return sum
}
func main() {
fmt.Println(sum(1, 2, 3))
fmt.Println(sum(10, 20))
}
만약 다양한 인수를 섞어서 사용하고 싶다면, …interface{} 로 받을 수 있다. (모든 타입이 빈 인터페이스를 포함하고 있기 때문에 가능함)
package main
import "fmt"
func Print(args ...interface{}) {
for _, arg := range args {
switch arg.(type) {
case bool:
val := arg.(bool) // 인터페이스 변환
fmt.Printf("type: %T\\n", val)
case float64:
val := arg.(float64) // 인터페이스 변환
fmt.Printf("type: %T\\n", val)
case int:
val := arg.(int) // 인터페이스 변환
fmt.Printf("type: %T\\n", val)
}
}
}
func main() {
Print(2, true, 3.14)
}
21.2 defer 지연 실행
함수가 종료하기 직전에 실행해야 하는 코드가 있을 수 있다. 혹은 리소스를 사용하고 반납을 해야 하는 것과 같이 반드시 실행해야 하는 코드가 있다면, 리소스를 생성할 때 바로 defer를 사용해서 필요한 명령을 전달할 수 있다(흔히 발생하는 닫지 않은 리소스로 인한 leak을 방지한다).
defer 예시에서 주의할 점은 defer는 역순으로 호출된다. (아래는 3, 2, 1 순서로 출력된다)
package main
import (
"fmt"
"os"
)
func main() {
f, err := os.Create("test.txt") // 파일 생성 -> 닫아줘야 한다
if err != nil {
fmt.Println("err")
return
}
defer fmt.Println("1")
defer f.Close() // defer로 처리해 놓으면 함수가 종료하기 전에 f를 닫아준다
defer fmt.Println("2")
fmt.Fprintln(f, "hello")
defer fmt.Println("3")
}
21.3 함수 타입 변수
함수 타입 변수란, 함수를 값으로 갖는 변수를 의미한다.
함수는 시작 번지를 가지고, 함수가 시작되면 순차적으로 시작한다고 가정할 때, CPU에서는 프로그램 카운터(program counter)가 증가하며 다음 실행 라인을 나타낸다. 이때 main() 함수에서 f() 함수를 실행하면, 프로그램 카운터가 f()함수의 시작 지점을 가리키게 된다.
즉 함수 시작 지점이 함수를 가리키는 값이고, 마치 포인터 처럼 함수를 가리킨다고 해서 함수 포인터(function pointer)라고 부른다.
func add(a,b int) int {
return a+b
}
함수 add()를 카리키는 함수 포인터는 아래와 같이 표현한다.
func add(int, int) int
함수 타입 변수를 활용한 예제를 살펴본다.
package main
import (
"fmt"
)
func add(a, b int) int {
return a + b
}
func mul(a, b int) int {
return a * b
}
func getOperator(op string) func(int, int) int {
if op == "+" {
return add
} else if op == "*" {
return mul
} else {
return nil
}
}
func main() {
var operator func(int, int) int // int 타입 인수 2개를 받아서 int 타입을 반환하는 함수 타입 변수 operator 선언
operator = getOperator("+")
result := operator(1, 2)
fmt.Println(result)
}
실제 활용 사례가 궁금하다.
21.4 함수 리터럴
함수 리터럴(function literal)은 이름 없는 함수로 함수명을 적지 않고 함수 타입 변수값으로 대입되는 함수값을 의미한다. (다른 언어의 익명함수 혹은 람다_Lambda와 동일하다)
예제를 살펴보면, 함수 타입 변수가 없이, 그냥 함수 자체를 정의한 것을 반환한다.
package main
import (
"fmt"
)
type opFunc func(a, b int) int
func getOperator(op string) opFunc {
if op == "+" {
// 함수 리터럴을 사용해서 더하기 함수 자체를(함수 이름이 없어짐) 정의하고 반환
return func(a, b int) int {
return a + b
}
} else if op == "*" {
return func(a, b int) int {
return a * b
}
} else {
return nil
}
}
func main() {
operator := getOperator("*")
result := operator(1, 2)
fmt.Println(result)
}
함수 리터럴은 필요한 변수를 내부 상태로 가질 수 있다. 함수 범위 내에서 유효할 것 같지만, 외부 변수를 실제로 변경할 수 있다.
함수 리터럴을 이용해서 원하는 함수를 그때그때 정의해서 함수 타입 변수값으로 사용할 수 있다. 한편 아래 예제에서 writeHello() 함수 입장에서는 인수로 Writer 함수 타입을 받는다. 실제로 어떤 동작을 할지는 호출했을 때 알 수 있게되는데, 이렇게 외부에서 로직을 주입하는 것을 의존성 주입(dependency injection)이라고 한다. 뭔가 아리송 하다.
package main
import (
"fmt"
"os"
)
type Writer func(string) // 함수 타입
func WriteHello(writer Writer) {
writer("Hello World")
}
func main() {
f, err := os.Create("test.txt")
if err != nil {
fmt.Println("failed")
return
}
defer f.Close()
WriteHello(func(msg string) {
fmt.Fprintln(f, msg)
})
}
22. 자료 구조
22.1 리스트
리스트(list)는 container 패키지에서 제공하는 자료 구조이다. 여러 데이터를 보관하는 배열과 비슷하다고 생각되지만, 배열이 연속된 메모리에 데이터를 저장하는 구조인 반면, 리스트는 연속되지 않는 메모리 공간에 데이터를 저장한다.
이러한 구조로 배열과 리스트는 데이터의 지역성(data locality)에 차이가 있다. 컴퓨터는 연산을 할 때 메모리에서 데이터를 가져와 캐시라는 임시 저장소에 보관하는데, 실제로 필요한 데이터만 가져오지 않고, 그 주변의 데이터를 가져온다. 보통은 높은 확률로 연산이 주변 데이터를 참조하기 때문에 효과적이다. 필요한 데이터가 인접해 있을 수록 데이터 처리 속도가 빨라지는데 데이터 지역성이 좋다고 한다. 배열은 연속된 메모리 이기 때문에 지역성이 리스트에 비해 좋다. 단, 요소 수가 적으면 데이터 지역성 때문에 배열이 효율적이지만, 삽입/삭제가 빈번한 연산이라면 리스트가 더 효율적이다.
리스트의 구조체 구조를 보면 요소들이 포인터로 연결된 링크드 리스트(Linked list) 형태인 것을 알 수 있다.
type Element struct {
value interface{}
Next *Element
Prev *Element
}
다음 예제에서 List의 기본적인 사용법과 순회 방법을 살펴본다.
package main
import (
"container/list"
"fmt"
)
func main() {
v := list.New()
e4 := v.PushBack(4)
e1 := v.PushFront(1)
v.InsertBefore(3, e4)
v.InsertAfter(2, e1)
for e := v.Front(); e != nil; e = e.Next() { // Next() 메서드는 현재 요소의 다음 요소를 반환한다. 다음 요소가 없으면 nil 반환
// (초기문)e는 v.Front() 부터; (조건문)e가 nil 값일 때까지; (후처리)e의 다음 요소로 넘어감
fmt.Print(e.Value, " ") // 1 2 3 4
}
}
22.2 링
링(ring)은 container 패키지에서 제공하는 자료 구조이다. 리스트와 유사한 구조인데, 맨 뒤의 요소와 맨 앞의 요소가 서로 연결된 자료 구조이다.
기본 예제를 살펴본다.
package main
import (
"container/ring"
"fmt"
)
func main() {
r := ring.New(5) // 요소가 5개인 링 생성
//n := r.Len()
// 순회하면서 모든 요소에 값 대입
for i := 0; i < r.Len(); i++ {
//r.Value = i // ring의 요소는 타입이 없나?, int를 넣으면 int가 저장됨.
//r.Value = 'A' + i
//이렇게 해도된다. 요소에 타입이 없는 것 같다.
if i%2 == 0 {
r.Value = 1
} else {
r.Value = '아'
}
r = r.Next()
}
for i := 0; i < r.Len(); i++ {
fmt.Printf("%c ", r.Value)
r = r.Next()
}
}
이러한 원형 구조이기 때문에, 개수가 고정되고 오래된 요소는 지워도 되는 경우에 적합한 자료 구조이다. 예를 들어, 문서 편집기의 실행 취소 기능(일정 개수의 명령을 저장하고, 실행 취소 할 수 있음, 너무 오래된 명령은 지워짐)에서 사용할 수 있다.
22.3 맵
맵(map)은 키와 값(key/value) 형태로 데이터를 저장하는 자료 구조이다. 언어에 따라서 딕셔너리(dictionary), 해시테이블(hash table), 해시맵(hashmap) 등으로 부른다.
맵은 키와 값의 쌍으로 데이터를 저장하고, 키를 사용해 접근하여 값을 저장하거나 변경할 수 있다.
맵의 기본 예제를 살펴본다.
package main
import (
"fmt"
)
type Product struct {
Name string
Prince int
}
func main() {
m := make(map[int]Product) // 맵 생성, map[key타입]value타입
m[1001] = Product{"볼펜", 500}
m[1002] = Product{"지우개", 500}
m[1003] = Product{"연필", 500}
m[1004] = Product{"샤프", 500}
delete(m, 1002)
delete(m, 1005) // 없는 값에 접근해도 에러가 발생하지는 않는다. v, ok := m[3] 으로 존재여부를 체크할 수 있다.
for k, v := range m {
fmt.Println(k, v)
}
}
맵은 hash() 함수로 만들어진다. 해시 함수는 결과값이 항상 일정 범위(개수)를 가진다. 같은 입력에 대해서는 같은 결과를 보장하고, 일정 범위에서 반복된다.
그래서 입력값(key)을 hash()에 넣어 결과값을 인덱스로 사용해 배열에 값(value)를 넣는 방식으로 사용하면 맵과 같은 형태를 만들 수 있다. 물론 이런 단순한 구현에서는 다른 입력값으로 같은 결과가 나올 수 있는 함정이 있기 때문에 리스트를 활용할 수 있다. 그래도 hash() 정도의 연산으로 고정된 시간에서 데이터를 저장, 사용할 수 있는 장점이 있는 것 같다.
배열(array)은 같은 타입의 데이터들로 이루어진 타입이다. 배열의 각 값은 요소(element)라고 하고, 이를 가리키는 위치값을 인덱스(index)라고 한다.
// var 변수명 [요소개수]타입
var t [5]float64
days := [3]string{"monday","tuesday","wednesday"}
x := [...]int{10,20,30} // 요소 개수 생략
var b = [2][5]int{ // 다중 배열
{1,2,3,4,5},
{6,7,8,9,10}, // 초기화 시 닫는 중괄호 } 가 마지막 요소와 같은 줄에 있지 않은 경우 마지막 항목 뒤에 쉼표, 를 찍어줘야 함!
} // 추후 항목이 늘어날 경우 쉼표를 찍지 않아서 생길 수 있는 오류를 방지하기 위해 존재하는 규칙
배열 선언 시 개수는 항상 상수여야 한다. 아니면 에러 발생!
package main
func main() {
x := 5
b := [x]int{1, 2, 3, 4, 5} // invalid array length x
}
배열 순회
package main
import "fmt"
func main() {
a := [5]int{1, 2, 3, 4, 5}
for _, v := range a {
fmt.Println(v)
}
var b = [2][5]int{ // 다중 배열
{1, 2, 3, 4, 5},
{6, 7, 8, 9, 10},
}
for _, b1 := range b {
for _, b2 := range b1 {
fmt.Print(b2, " ")
}
fmt.Println()
}
}
배열의 핵심
배열은 연속된 메모리다.
컴퓨터는 인덱스와 타입 크기를 사용해서 메모리 주소를 찾는다.
중요 공식
요소 위치 = 배열 시작 주소 + (인덱스 X 타입크기) → a 배열 시작 주소가 100번지 라면 a[3] 주소는 100 + (3*4) = 112번지
배열 크기 = 타입크기 X 항목개수 → [5]int = 8*5 = 40bytes
왜 두 공식의 int 타입크기를 다르게 한거지? 오타?
13. 구조체
여러 필드(field)를 묶어서 하나의 구조체(structure)를 만든다. 구조체는 다른 타입의 값들을 변수 하나로 묶어준다.
프로그래밍의 역사는 객체 간 결합도(객체 간 의존관계)는 낮추고, 연관있는 데이터 간 응집도를 올리는 방향으로 흘러왔다. 함수와 구조체 모드 응집도를 증가시키는 역할을 한다.
→ 구조체의 등작으로, 프로그래머는 개별 데이터의 조작/연산보다는 구조체 간의 관계와 상호작용 중심으로 변화하게 되었다.
type 타입명 struct {
필드명 타입
}
학생(Student) 구조체를 만들고, 이름, 반과 같은 정보를 넣는다. 구조체의 각 필드는 .을 통해서 접근할 수 있다.
package main
import "fmt"
func main() {
type Student struct {
name string
class int
}
var std1 Student
std1.name = "홍"
std1.class = 1
fmt.Println(std1.name, std1.class)
// 초기화를 아래와 같이 해줄 수도 있다.
std2 := Student{"김", 2}
fmt.Println(std2.name, std2.class)
}
구조체를 포함하는 구조체를 만들 때,
내장 타입처럼 포함할 때는 instance.StructName.fieldName 으로 접근한다.
포함된 필드 방식으로 사용할 수 있는데, 이때는 instance.fieldName으로 포함된 구조체 필드를 바로 접근할 수도 있다.
필드 배치 순서에 따른 구조체 크기 변화
구조체의 인스턴스가 생성되면 구조체 필드의 크기를 더한 만큼의 메모리 공간을 차지하게 된다.
다만 필드 배치 순서에 따라 구조체 크기가 달라 질 수 있는데, 메모리 정렬(Memory Alignment)를 고려해서 8의 배수인 메모리 주소에 데이터를 할당하도록 동작하기 때문에, 만약 적은 사이즈의 필드가 있는 경우는 메모리 패딩(memory Padding)을 넣고, 다음 8배수 공간에 데이터를 할당하기 때문이다.
메모리 정렬이란 컴퓨터가 데이터에 효과적으로 접근하고자 메모리를 일정 크기 간격으로 정렬하는 것을 말한다.
package main
import (
"fmt"
"unsafe"
)
func main() {
type User struct {
Age int32
Score float64
}
user := User{23, 77.2}
fmt.Println(unsafe.Sizeof(user.Age), unsafe.Sizeof(user.Score)) // 4, 8
fmt.Println(unsafe.Sizeof(user)) // 16
}
이러한 이유로 구조체에서 메모리 패딩을 고려한 필드 배치방법을 사용해야 한다.
→ 8 bytes 보다 작은 필든느 8 bytes 크기(단위)를 고려해서 몰아서 배치하자.
14. 포인터
포인터는 메모리 주소를 값으로 갖는 타입이다. 포인터 변수를 초기화 하지 않으면 기본 값은 nil이다.
package main
import (
"fmt"
)
func main() {
var a int
var p1 *int
p1 = &a // a의 메모리 주소를 포인터 변수 p에 대입
var p2 *int = &a
fmt.Println(p1 == p2) // == 연산을 사용해 포인터가 같은 메모리 공가늘 가리키는 지 확인
}
포인터는 왜 쓸까?
→ 변수 대입이나 함수 인수 전달은 항상 값 복사를 하기 때문에, 메모리 공간을 사용하는 문제와 큰 메모리 공간을 복사할 때 발생하는 성능 문제가 있다.
→ 또한 다른 공간으로 복사되기 때문에 실제 변수의 값에 변경 사항이 적용되지 않는다.
구조체를 생성해 포인터 변수 초기화 하기
구조체 변수를 별도로 생성하지 않고, 곧바로 포인터 변수에 구조체를 생성해 주소를 초기값으로 대입하는 방법
방식1) Data타입 구조체 변수 data를 선언하고, data변수의 주소를 반환하여 대입
var data Data
var p *Data = &data
방식2) *Data 타입 구조체 변수 p를 선언하고, Data 구조체를 만들어서 주소를 반환
var p *Data = &Data{}
→ 이렇게 하면 포인터 변수 p만 가지고도 구조체의 필드값에 접근하고 변경할 수 있다. (실제 Data 구조체에 대한 변수를 생성하지 않음)
방식3) new() 내장 함수: 포인터값을 별도의 변수를 선언하지 않고 초기화 할 수도 있는데, new 내장 함수를 이용하면 더 간단히 표현할 수 있다.
p1 := &Data{} // &를 사용하는 초기화
var p2 = new(Data) // new()를 사용하는 초기화
인스턴스
인스턴스란 메모리에 할당된 데이터의 실체이다. 포인터를 이용해서 인스턴스에 접근할 수 있다.
구조체 포인터를 함수 매개변수로 받는다는 말은 구조체 인스턴스로 입력을 받겠다는 것과 동일하다.
Go 언어는 가비지 컬렉터(Garbage Collector)라는 메모리 정리 기능을 제공하는데, 카비지 컬렉터가 일정 간격으로 메모리에 쓸모 없어진 데이터를 정리한다.
쓸모 없어진 데이터: 아무도 찾지 않는 데이터는 쓸모 없는 데이터다. 예를 들어, 함수가 종료되면 함수에서 사용한 인스턴스는 더 이상 쓸모가 없게 된다.
스택 메모리와 힙 메모리
대부분의 프로그래밍 언어는 메모리를 할당할 때 스택 메모리 영역 또는 힙 메모리 영역을 사용한다. 이론상 스택 메모리 영역이 효율적이지만, 스택 메모리는 함수 내부에서만 사용 가능한 영역이다. 그래서 함수 외부로 공개되는 메모리 공간은 힙 메모리 공간을 할당한다.
자바는 클래스 타입을 힙에, 기본 타입을 스택에 할당한다. Go에서는 탈출 검사(escape anlaysis)를 해서 어느 메모리에 할당할지 결정한다. 즉 Go 언어는 어떤 타입이나 메모리 할당 공간이 함수 외부로 공개되는지 여부를 자동으로 검사해서 스택 메모리에 할당할지 힙 메모리에 할당할지 결정한다.
package main
import (
"fmt"
)
type User struct {
Name string
Age int
}
func NewUser(name string, age int) *User {
var u = User{name, age}
return &u // 보통 함수가 종료하면, 함수 내 선언된 변수는 사라진다. 탈출 분석을 통해 u 메로리가 사라지지 않음
}
func main() {
userPointer := NewUser("AAA", 22)
fmt.Println(userPointer)
}
Go의 스택 메모리는 계속 증가되는 동적 메모리 풀로, 일정한 크기를 같는 C/C++과 비교해 메모리 효율성 높고, 스택 고갈 문제도 발생하지 않는다.
15. 문자열
문자열은 문자 집합을 나타내는 타입으로 string이다. 문자열은 큰 따옴표나 백쿼트로 묶어서 표시한다.
Go는 UTF-8 문자코드를 표준 문자 코드로 사용한다. UTF-8은 자주 사용되는 영문자, 숫자 일부 특수문자를 1바이트로 표현하고, 그 외 다른 문자들은 2~3바이트로 표현한다. (한글 사용 가능)
rune 타입
문자 하나를 표현하기 위해 rune 타입을 사용한다. UTF-8은 한 글자가 1~3바이트 크기이기 때문에, UTF-8 문자값을 가지려면 3바이트가 필요하다. Go에서는 기본 타입에서 3 바이트 정수 타입은 제공되지 않기 때문에 rune 타입은 4 바이트 정수 타입인 int32 타입의 별칭 타입이다.
string 타입을 []rune으로 변환하면, 각 글자들로 이뤄진 배열로 변환된다. 그래서 각각이 1바이트로 8이 된다.
[]byte 타입
string 타입과 []byte 타입은 상호 타입 변환이 가능하다. []byte는 byte 즉 1바이트 부호 없는 정수 타입의 가변 길이 배열이다. 문자열은 메모리에 있는 데이터고, 메모리는 1바이트 단위로 저장되기 때문에 모든 문자열은 1바이트 배열로 변환 가능하다.
파일을 쓰거나, 네트워크로 데이터를 전송하는 경우, io.Writer 인터페이스를 사용하고, io.Writer 인터페이스는 []byte 타입을 인수로 받기 때문에 []byte 타입으로 변환해야 한다. 문자열을 쉽게 전송하고자 string에서 []byte 타입으로 변환을 지원한다.
문자열 구조
string은 필드가 1개인 구조체이다. 첫번째 필드 Data는 uintptr 타입으로 문자열의 데이터가 있는 메모리 주소를 나타내는 일정의 포인터이고, 두번째 필드 Len은 문자열의 길이를 나타낸다.
type StringHeader struct {
Data uintptr
Len int
}
→ str2 변수에 str1 변수를 대입하면, str1의 Data와 Len값만 str2에 복사한다. 문자열 자체가 복사되지는 않는다.
문자열과 immutable
string 타입이 가리키는 문자열의 일부만 변경 할 수 없다. 변경하려면 슬라이스로 타입 변환하고, 변경하는 방식을 취할 수 있다.
package main
func main() {
str := "Hello world"
str = "How are you"
str[2] = 'a' // cannot assign to str[2] (neither addressable nor a map index expression)
}
→ 문자열의 합산을 하면 기존 문자열 메모리 공간을 건드리지 않고, 새로운 메모리 공간을 만들어서 두 문자열을 합치기 때문에 주소값이 변경된다. (문자열 불변 원칙이 준수 된다.)
이로 인해 메모리 낭비가 있을 수 있는데, strings 패키지의 Builder를 이용해서 메모리 낭비를 줄일 수 있다.
16. 패키지
16.01. 패키지
패지키(package)란 Go에서 코드를 묶는 가장 큰 단위 이다.
함수로 코드 블록을, 구조체로 데이터를, 패키지로 함수와 구조체와 그 외 코드를 묶는다. main 패키지는 특별한 패키지로 프로그램 시작점을 포함한 패키지이다. main() 함수와 다른 함수, 구조체 등을 가진다. 외부 패키지는 main() 을 가지지 않는다.
한 프로그램은 main 패키지 외에 다수의 다른 패키지를 포함할 수 있다.
이러한 패키지를 import해 사용한다.
패키지를 가져오면 해당 패키지명을 쓰고 . 연산자를 사용해 패키지에서 제공하는 함수, 구조체 등에 접근할 수 있다.
import (
"fmt"
"math/rand"
"text/template"
htemplate "html/template" // 동일한 패키지 명에는 별칭 htemplate
_ "github.com/mattn/go-sqllite3" // 패키지를 import하면 무조건 사용해야한다.
// 패키지를 직접 사용하지 않지만 부가효과를 얻는 경우 _ 을 패키지명 앞에 붙여준다.
// 부과효과: 패키지가 초기화 되면서 실행되는 코드에 따른 효과
)
fmt.Println("Hello World") // fmt 패키지명 . Println() 함수명
fmt.Println(rand.Int()) // 경로가 있느 패키지인 math/rand 패키지의 경우는 마지막 폴더명인 rand만 사용한다.
패키지를 import 하면 컴파일러는 패키지 내 전역 변수를 초기화 한다. 그런 다음 패키지에 init() 함수가 있다면 호출해 패키지를 초기화 한다. init() 함수는 반드시 입력 매개변수가 없고, 반환값도 없는 함수여야 한다.
이때 패키지의 초기화 함수인 init() 함수 기능만 사용하기 원할 경우 밑줄 _을 이용해서 import 한다.
16.02. 모듈
모듈은 패키지를 모아 놓은 Go의 프로젝트 단위로 Go 1.16부터 기본이 됐다.
이전에는 Go 모듈을 만들지 않는Go 코드는 모두 GOPATH/src 아래 폴더 아래에 있어야 했지만, 모듈이 기본이 되면서 모든 Go 코드는 Go 모듈 아래에 있어야 한다.
go build를 사용하려면 반드시 Go 모듈 루트 폴더에 go.mod 파일이 있어야 한다. go build를 통해 실행 파일을 만들 때, go.mod와 외부 저장소 패키지 버전 정보를 담고 있는 go.sum 파일을 통해 외부 패키지와 모듈 내 패키지를 합쳐서 실행 파일을 만든다.
go mod init 패키지명
go.mod : Go 버전과 외부 패키지 등이 명시된 파일 go.sum: 외부 저장소 패키지 버전 정보를 담고 있는 파일, 패키지 위조 여부 검사를 위한 checksum 결과가 있다.
package main
import (
"fmt" // go가 설치되면 같이 설치되는 표준 패키지
"goprojects/usepkg/custompkg" // 현재 모듈에 속한 패키지
"github.com/guptarohit/asciigraph" // 외부 저장소 패키지
"github.com/tuckersGo/musthaveGo/ch16/expkg"
)
func main() {
custompkg.PrintCustom()
expkg.PrintSample()
data := []float64{3, 4, 5, 5, 5, 2, 13, 5, 8, 6, 4}
graph := asciigraph.Plot(data)
fmt.Println(graph)
}
5. go mod tidy 로 모듈에 필요한 패키지를 찾아서 다운로드 해주고, 필요한 패키지 정보를 go.mod 파일과 go.sum 파일에 적어주게 된다. 다운 받은 외부 패키지인 asciigraph 패키지와 expkg 패키지는 GOPATH/pkg/mod 폴더에 버전별로 저장되어 있다.
6. 파일 내용: go.mod와 go.sum에 필요한 패키지의 버전 정보가 기입되어서 항상 같은 버전의 패키지가 사용되므로, 버전 업데이트에 따른 문제가 발생하지 않는다.