
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- windows
- Karpenter
- 묘공단
- Azure
- ansible
- KEDA
- Object Storage
- vscode
- HPA
- minIO
- Timeout
- AutoScaling
- ubuntu
- VPA
- go
- calico
- kubernetes
- 쿠버네티스
- AKS
- upgrade
- aws
- EKS
- WSL
- ipam
- cilium
- directpv
- gateway api
- 업그레이드
- curl
- 컨테이너
- Today
- Total
a story
[1] MinIO 개요 본문
이번 게시물에서는 오브젝트 스토리지 MinIO에 대해서 알아보겠습니다.
목차
- Block, File, Object Storage
- MinIO 개요
- MinIO 주요 동작
1. Block, File, Object Storage
MinIO는 오브젝트 스토리지 솔루션입니다. 왜 MinIO가 오브젝트 스토리지를 선택하게 되었는지 기본적인 스토리지 개념부터 살펴보겠습니다.
스토리지에 데이터의 저장 방식에 따라 블록 스토리지(Block Storage), 파일 스토리지(File Storage), 오브젝트 스토리지(Object Storage)로 나뉩니다.
블록 스토리지

출처: https://www.youtube.com/watch?v=6vFqHhgPHjI
블록 스토리지에서는 데이터를 고정 크기의 "block"의 연속(sequence)으로 취급합니다. 각 파일은 실제로 여러 block에 걸쳐 저장됩니다.
이 block의 크기는 어떤 데이터가 저장되느냐에 따라 적절하게 조정이 가능합니다. 예를 들어, disk block size는 4KB이지만 특정 데이터베이스의 I/O가 16KB이 일 때, 이를 일치시킬 수 있습니다.
모든 block들이 함께 저장될 필요는 없으며, 최적의 성능을 제공하기 위해서 알맞게 정렬될 수 있습니다. 이는 보통 소프트웨어적으로 처리되며, 사용자가 직접 block의 정렬을 수행하거나 하지 않습니다.
다만 메타데이터(metadata)를 다루는데 제한이 있습니다. 파일명과 같은 일부 데이터가 될 수 있지만, 그 이상으로 검색을 효과적으로 하기는 어렵습니다.
데이터 저장에 높은 일관성을 제공하며, block 수준에서 고도로 구조화(저장 구조나 접근 방식이 체계화 됨)되어 있습니다.
블록 스토리지는 iSCSI, 파이버 채널, SATA, SAS 등과 같은 일반적인 인터페이스를 통해 block 단위로 데이터를 가져옵니다.
블록 스토리지는 기본적으로 단순한 저장 공간이기 때문에, 이를 실제 파일 단위로 관리하려면 OS에 알맞은 파일 시스템(NTFS, XFS, ext4 등)을 위에 얹어야 합니다. 이 과정에서 원하는 기능(권한 관리, 트랜잭션, 캐시 등)이 제공되지만, 동시에 성능이나 리소스 측면에서 오버헤드도 생깁니다.
블록 스토리지 자체는 단일 Disk 형태로 redundancy를 제공하기 위해서는 Parity나 HA 방식의 RAID 방식을 취하는데 이로 인해서 사용하지 못하는 디스크 공간이 생기고, 또한 이를 전문적으로 지원하는 벤더의 H/W 혹은 S/W에 대한 비용도 만만치 않습니다.
파일 스토리지

출처: https://www.youtube.com/watch?v=6vFqHhgPHjI
파일은 전체 형태로 저장되며, 저장된 형식 그대로 폴더/파일 경로 방식으로 접근됩니다.
저장되는 메타데이터는 제한적이며, 생성 날짜, 수정 날짜, 파일 크기 및 추가 속성만 포함됩니다. 이러한 메타데이터 자체로 검색이 완전하게 제공되기는 어렵습니다.
파일은 동시 쓰기로 인한 손상을 방지를 위해 단일 작성자에게 'locked'될 수 있으며, 작업이 완료되면 다른 작성자가 해당 파일을 수정할 수 있습니다.
일반적으로 블록 스토리지나 오브젝트 스토리지 위에 구축되며, SMB나 NFS와 같은 특정 파일 스토리지 프로토콜을 통해 접근된다. 보통 통신에 이용되는 SMB나 NFS와 같은 프로토콜로 인한 어느 정도의 오버헤드가 발생합니다.
그리고 파일 스토리지는 Flat한 구조의 파일 저장 방식이 아니기 때문에, 특정 폴더에 파일이 많아지는 경우 파일 리스트 조회나 파일에 대한 요청에서 하드웨어 스펙(캐시 등)에 따라 크게 속도 저하가 발생하는 경우도 발생합니다.
파일 스토리지 또한 블록 스토리지에 위치하고, 이로 인해서 HA(High Availablilty)를 제공하기 위한 하드웨어나 네트워크 비용이 높습니다. 또한 블록 스토리지의 제약에 따라 확장성에 제한이 있습니다.
파일 스토리지에 대한 공유와 관리 자체가 큰 관리 오버헤드가 되기도 합니다.
오브젝트 스토리지

출처: https://www.youtube.com/watch?v=6vFqHhgPHjI
오브젝트 스토리지에서 파일은 메타데이터, Object ID 및 추가 속성(RBAC 정보 등)을 포함한 분산된 조각(shard) 형태로 저장되며, 요청 시 재조립됩니다.
무제한의 메타데이터를 추가할 수 있어 고급 검색 기능을 지원합니다.
파일은 'locked'할 수는 없지만, 버저닝(versioning)을 활성화 하여 데이터 무결성을 유지하고 규제 요건을 충족할 수 있습니다. 변경에 대한 레코드가 없이는 파일의 변경을 할 수 없게하거나 혹은 이전 버전으로 롤백할 수 있습니다.
공통 인터페이스를 유지하면서 스토리지를 지속적으로 확장할 수 있어 무제한 확장성이 가능합니다. 프론트엔드 인터페이스가 사용자 요청을 처리하는 동안 백엔드 스토리지를 추가하여 사용자에 투명하게 확장을 처리할 수 있습니다.
이 스토리지 프로토콜은 TCP/HTTP 기반의 표준 REST API를 활용하여 높은 효율성을 갖추고 있습니다.
오브젝트 스토리지는 범용 하드웨어를 사용할 수 있으며, 고가의 RAID 장비 없이도 'Erasure coding'를 통해 매우 효율적인 중복성을 제공합니다. 이후 살펴보겠지만 Erasure coding이란 데이터를 여러 조각(shard)으로 나누고, 패리티(parity) 정보를 추가하여 일부 조각이 손실되어도 원본 데이터를 복구할 수 있게 하는 기술입니다. (이 방식 대부분의 오브젝트 스토리지 솔루션에서 각자의 알고리즘을 통해서 제공하고 있는 걸로 보입니다)
또한, 지리적으로 다양한 위치에 엔드포인트를 배치하고 자동으로 복제할 수 있어 글로벌 확장이 저렴하게 이루어집니다.
MinIO에서 제공하는 영상을 바탕으로 살펴보면 마치 오브젝트 스토리지가 모든 스토리지에 앞선 스토리지 기술처럼 느껴지지만, 실제로는 워크로드의 특성에 따른 스토리지를 선택해야 하는 것이 알맞습니다.
출처: https://www.youtube.com/watch?v=Zs4VNc1tSNc
블록 스토리지 사용 사례
서버의 부팅 볼륨이나 로컬 스토리지에 적합하며, 또한 데이터베이스, 미디어 렌더링과 같은 빠른 IO 속도를 요구하는 유형의 워크로드에 적합합니다.
특히 높은 일관성을 요구하는 IO 작업에는 블록 스토리지가 알맞습니다. 이 경우에는 네트워크나 프로토콜 오버헤드를 가지는 파일스토리지가 적합하지 않으며, 또한 오브젝트 스토리지의 IO는 REST API이기 때문에 적합하지 않습니다.
저가형의 높은 용량을 가진 디스크로 구성된 블록 스토리지는 백업용으로 사용하기에도 적합합니다.
파일 스토리지 사용 사례
다수의 사용자가 파일을 저장하고 중요 데이터를 관리하는데 유형의 파일 공유나 이미지, 비디오 등 많은 양의 미디어를 저장하기에 적합니다.
일반적으로 웹 서버들에서 공유되는 웹 컨텐츠를 공유하는 위치에 저장하기에도 적합합니다.
오브젝트 스토리지 사용 사례
Box나 Dropbox와 같은 서비스와 같이 오브젝트 스토리지를 통해서 문서/파일 공유를 지원할 수 있습니다.
정적 웹사이트도 오브젝트 스토리지를 통해서 호스팅할 수 있으며, 또한 무제한 확장 가능하다는 점에서 전통적인 백업 아카이빙 수단을 대체하고 있습니다.
Data 분석/AI/ML과 같은 워크로드에서 오브젝트 스토리지는 방대한 양의 메타데이터를 유연하게 저장하고 관리할 수 있기 때문에, 이를 활용하면 대규모 데이터 분석 작업에 매우 적합합니다.
요약하자면 아래와 같습니다.

출처: https://www.youtube.com/watch?v=Zs4VNc1tSNc
아무래도 최근 클라우드 환경에서 기본적으로 S3 기반의 오브젝트 스토리지 기술이 넓리 쓰이고 있고, 또한 AI 시대에 데이터가 폭증하면서 필요한 데이터를 저장하기 위한 공간으로 오브젝트 스토리지 기술이 높은 주목을 받는 것으로 이해됩니다.
다만 기존 스토리지 기술에 익숙한 사용자에게 오브젝트 스토리지의 비파일적 접근 방식과 컨셉에 혼란이 있고, 이를 보완하기 위해서 NFS나 blobfuse와 같은 프로토콜을 사용하는 사용 사례에서는 오히려 오버헤드가 발생하기도 합니다.
즉, 오브젝트 스토리지를 적절하게 사용하기 위해서 단순히 파일 처럼 사용하는 것이 아닌, SDK를 사용하거나 REST API 방식으로 스토리지를 사용하는 방식으로 사고를 전환해야 합니다.
2. MinIO 개요
MinIO는 앞서 살펴본 유연성, 확장성, 스케일 아웃 구조, 성능, 다양한 아키텍처 지원, 그리고 하이브리드 멀티 클라우드 환경에 대한 대응력을 바탕으로, 오브젝트 스토리지 솔루션을 제공합니다.
MinIO, 그리고 오브젝트 스토리지에서 사용되는 몇가지 용어를 먼저 살펴보고 가겠습니다.
오브젝트
오브젝트란 바이너리 데이터를 의미하며 때때로 Binary Large Object(BLOB)이라도 합니다. Blob은 이미지, 오디오 파일, 스프레드시트 혹은 바이너리 실행 코드 일 수도 있습니다. MinIO와 같은 오브젝트 스토리지 플랫폼은 이러한 Blob의 저장, 조회, 검색하는데 특화된 도구와 기능을 제공합니다.
버킷(Bucket)
MinIO 오브젝트 스토리지는 오브젝트를 정리하기 위해서 버킷을 사용합니다. 오브젝트를 버킷은 파일시스템의 폴더나 디렉터리와 유사하며, 각 버킷에는 임의의 수의 오브젝트를 저장할 수 있습니다. MinIO의 버킷은 AWS S3의 버킷과 동일한 기능을 제공합니다.
MinIO server, server pool, cluster
MinIO 배포는 하나 이상의 minio server 노드가 실행되는 스토리지와 컴퓨트 리소스 세트로 구성되며, 이것이 하나의 오브젝트 스토리지 저장소 처럼 동작합니다. MinIO의 standalone instance는 하나의 minio server 노드와 하나의 server pool로 구성됩니다.
이 때 배포 방식은 아래와 같습니다.
참고: https://docs.min.io/community/minio-object-store/operations/deployments/installation.html
- Single-Node Single-Drive (SNSD or “Standalone”)
- 단일 MinIO server에 단일 드라이브나 폴더를 사용해 데이터를 저장합니다.
- 로컬 개발이나 평가에 적합합니다.
- Single-Node Multi-Drive (SNMD or “Standalone Multi-Drive”)
- 단일 MinIO server에 멀티 드라이브나 폴더를 사용하는 경우입니다.
- 낮은 성능, 스케일, 용량을 요구하는 워크로드에 적합합니다.
- Multi-Node Multi-Drive (MNMD or “Distributed”)
- 멀티 MinIO server에 각각 멀티 드라이브를 가지고 구성된 경우입니다.
- 엔터프라이즈급의 높은 성능을 가진 오브젝트 스토리지로 활용됩니다.
용어가 다소 헷갈리는데 MinIO server를 MinIO 소프트웨어가 실행되는 하나의 프로세스 또는 노드라고 보고 이를 데이터를 저장하고 처리하는 기본 단위라고 한다면, 이러한 MinIO 서버 노드와 드라이브를 묶어서 Server Pool이라고 할 수 있습니다.
아래는 각 4개 드라이브를 가진 4개 MinIO server 노드로 단일 Server Pool을 생성하는 명령입니다.

여러 MinIO 서버 노드를 하나의 풀로 묶어서 저장소와 리소스를 공유하며 오브젝트 저장 요청을 처리합니다. 하나 이상의 Server Pool로 구성된 전체 MinIO 배포 환경을 Cluster라고 합니다.
아래는 각 4개 드라이브를 가진 4개 MinIO server 노드로 구성된 2개의 Server Pool으로 구성된 Cluster를 생성하는 명령입니다.

일단 여기까지 살펴보고, 이후 실습을 하면서 이론을 보충해보겠습니다.
3. MinIO 주요 동작
MinIO에서 오브젝트를 처리하는 주요 동작을 통해 오브젝트 스토리지의 동작 매커니즘에 대해 살펴보겠습니다.
PUT 요청
참고: https://www.youtube.com/watch?v=GNBWHjB7PP0

MinIO에서 monalisa.jpg라는 이미지 파일을 오브젝트 스토리지에 저장하는 PUT 요청이 있다고 합니다.
그림에서 monalisa.jpg라는 파일명은 Hash -> Mod 를 거칩니다.
1) 파일명은 Hash 처리를 통해서 고유한 해시값으로 생성됩니다.
2) 해시 값은 나머지(modulus) 함수를 를 통해어 데이터가 최종적으로 저장될 특정 드라이브 집합을 결정합니다.
동시에 이미지 자체는 Erasure code engine라는 처리됩니다.
이것은 이미지라는 오브젝트 자체를 각각의 data와 parity block으로 자릅니다.
잘려진 오브젝트는 modulus 함수를 통해 얻어진 드라이브 집합에 각 저장됩니다.
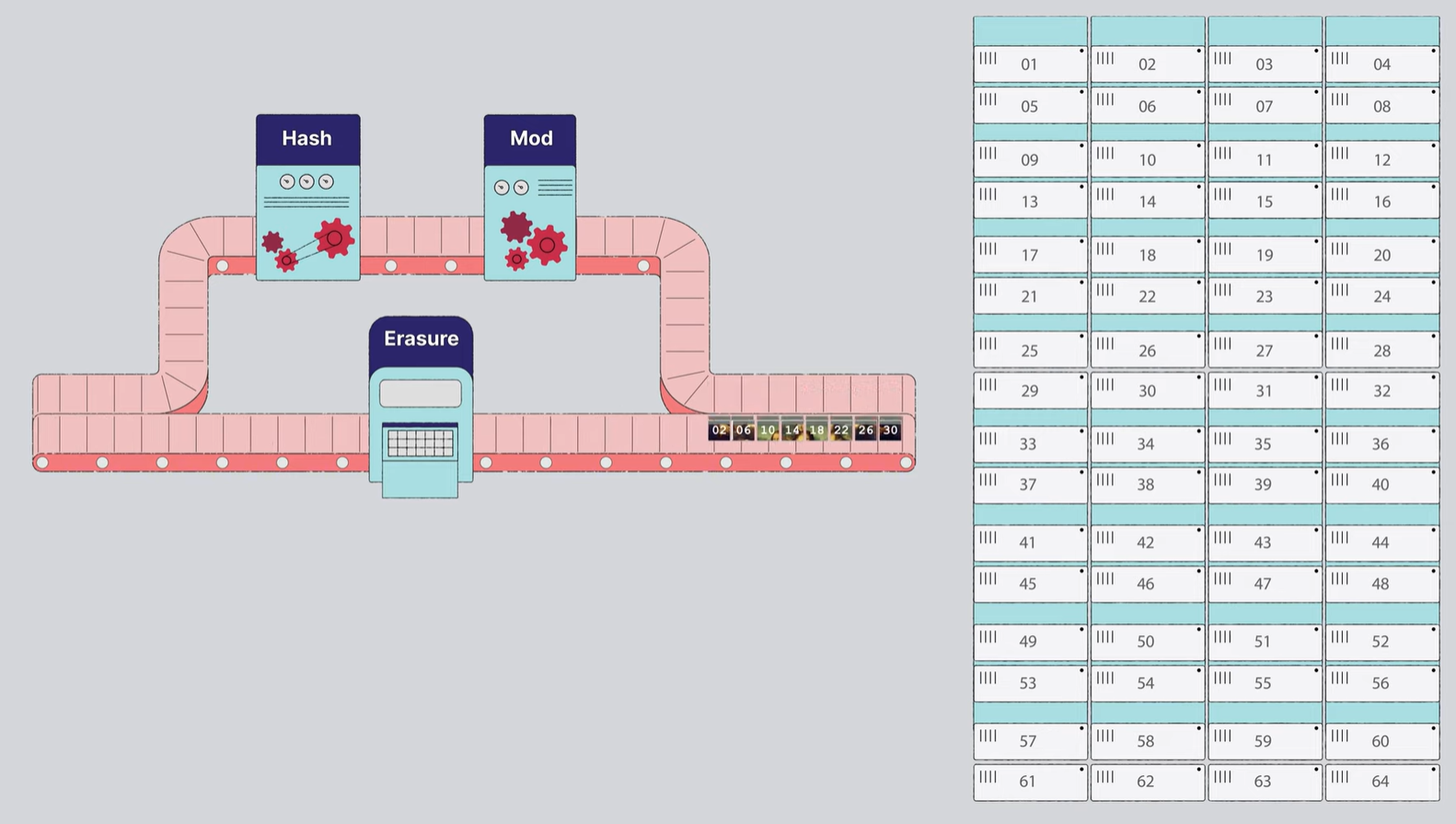
이 그림에서는 결국 02, 06, 10, 14, 18, 22, 26, 30 의 erasure set에 저장이 됩니다.
GET 요청
특정 파일에 대한 GET 요청이 들어왔을 때는 아래와 같습니다.
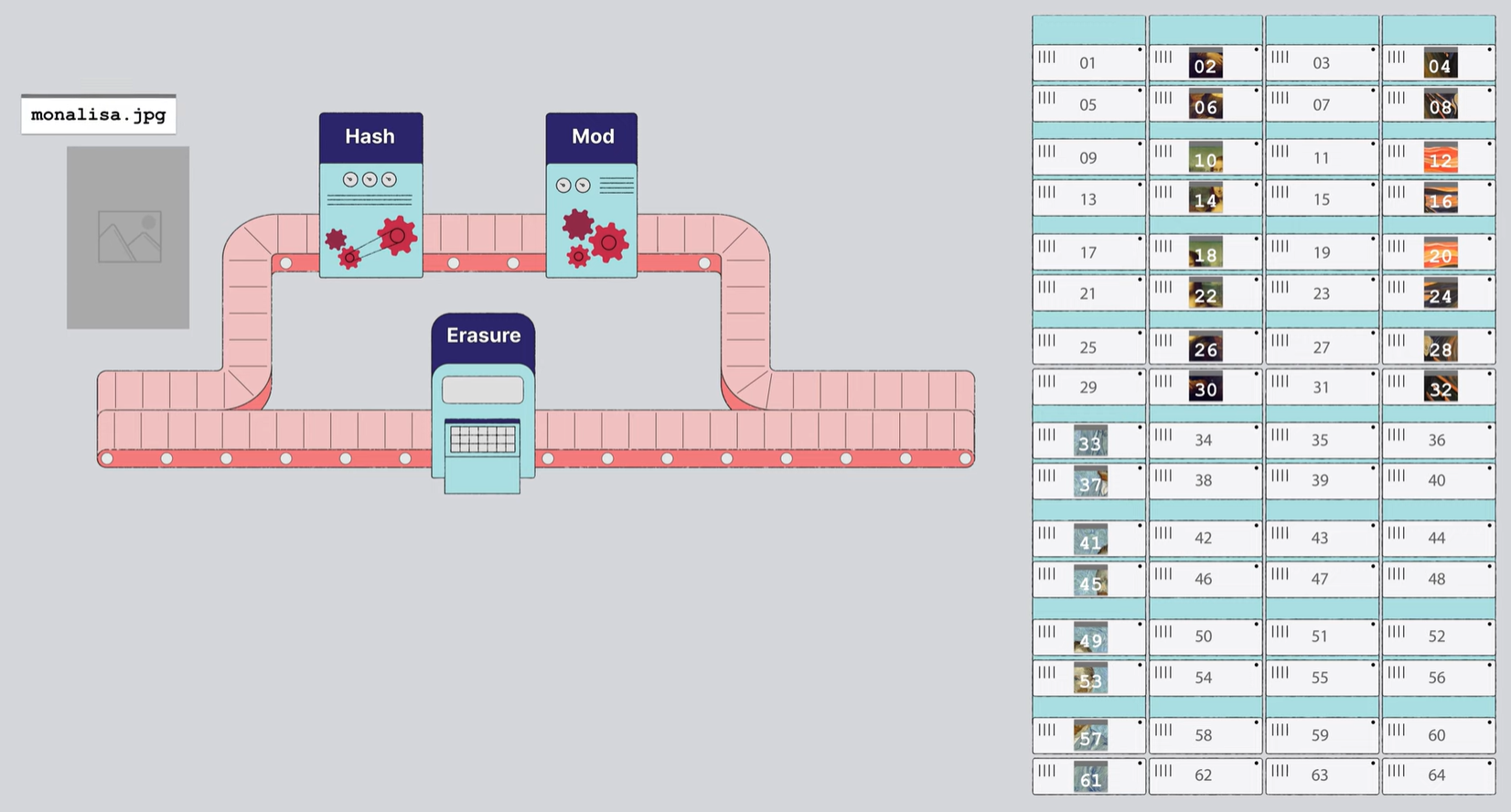
파일명은 동일하게 Hash -> Mod 로 동작하여 파일명에 대한 고유한 해시값 그리고 저장소의 특정 드라이브 집합에 대한 정보로 도출됩니다. Mod의 최종 결과는 실제 데이터가 위치한 드라이브에 대한 정보입니다.

이 정보를 바탕으로 데이터가 회수되면, 이 오브젝트를 다시 Erasure code engine을 통해서 이미지로 만들어 냅니다.
Erasure Code
참고: https://www.youtube.com/watch?v=sxcz6U0fUpo
GET과 PUT의 요청 처리를 보면 결국 Erasure code라는 처리를 하는데, 이것이 오브젝트 스토리지의 저장과 신뢰성을 확보하기 위한 주요한 알고리즘입니다.
Erasure Code는 데이터를 여러 저장소에 분산시키기 위해 수학적 알고리즘을 사용하는 데이터 보호 방식입니다. 이 방식은 Parity block을 통해 복원력을 제공하며, 손실된 데이터를 다시 조합할 수 있도록 합니다.

이 예시에서 하나의 오브젝트는 Erasure code를 통해 5개의 data block과 3개의 parity block으로 나눠집니다. Erasure stripe size는 8이고, 8개 노드에 각 8개 드라이브가 있을 때(총 64개의 드라이브)에서 총 8개의 erasure set이 생성됩니다.
이때 data block은 오브젝트 data를 조각으로 나눴을 때 한 조각 사이즈와 동일합니다. parity block은 수학적 코드를 담고 있으며, data block이 손실되었을 때 오브젝트를 재조합하기 위해서 사용됩니다. 이 구성에서 총 3개 드라이브에 대한 실패에 대해서도 오브젝트를 복구할 수 있습니다.
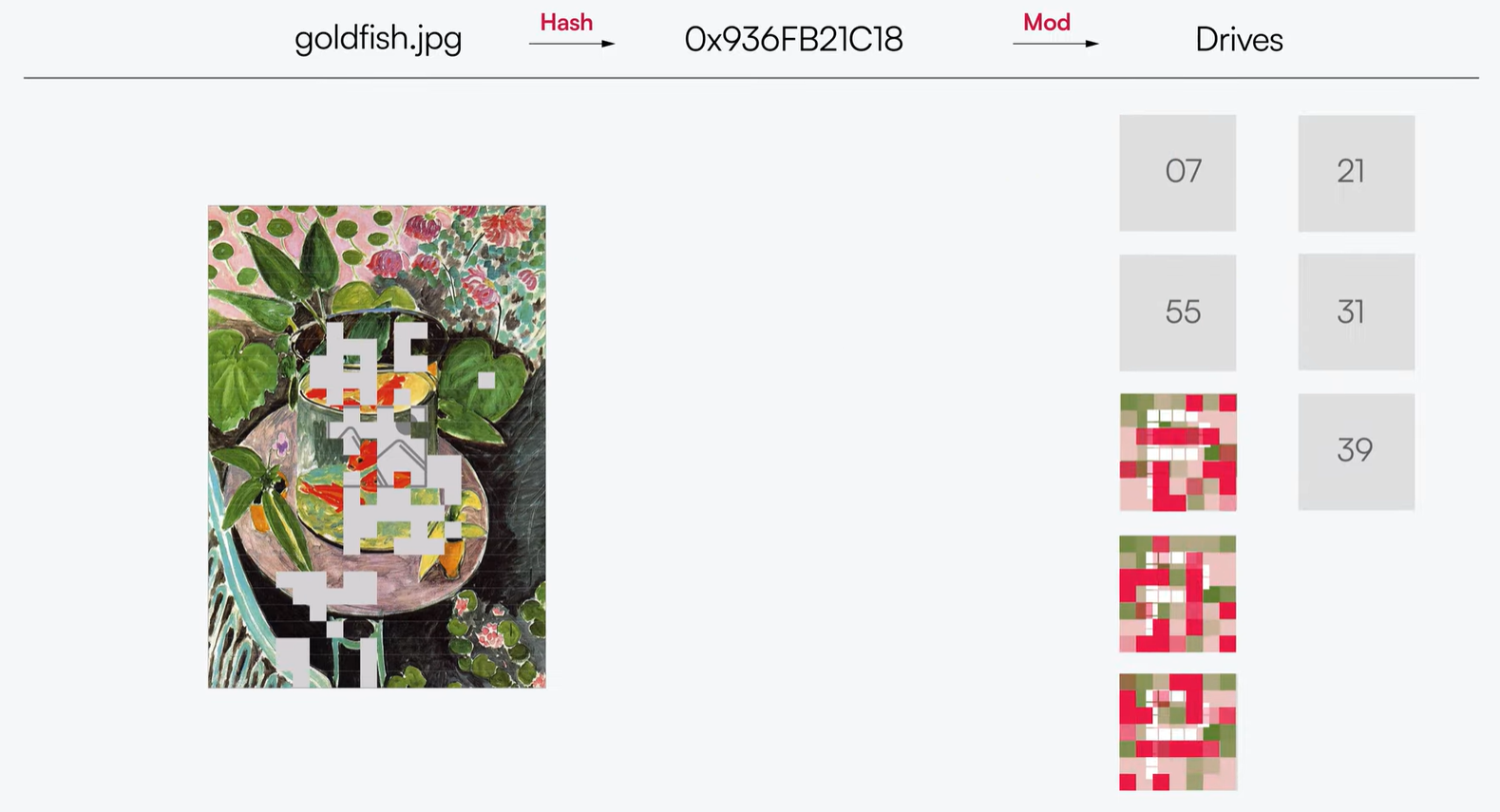
이러한 Erasure code가 실제로 RAID나 복제 기술와 같은 기존 기술보다 훨씬 낮은 오버헤드로 객체 수준의 복구를 제공한다고 합니다.
Bit rot healing
만약 손상된 data block이 있는 경우 그대로 두는 것은 아닙니다. MinIO는 저장된 데이터를 보호하기 위해 Bit Rot healing 기능을 구현합니다.
Bit Rot은 저장 장치에서 발생할 수 있는 무작위적이고 조용한 데이터 손상 현상입니다. 이러한 손상은 사용자 활동에 의해 발생하는 것이 아니며, 운영 체제 또한 이 변화를 인지하거나 사용자 또는 관리자에게 알릴 수 없습니다.
MinIO는 객체의 무결성을 확인하기 위해 해싱 알고리즘을 사용합니다. 이 알고리즘은 객체에 대해 GET 또는 HEAD 요청이 있을 때 자동으로 수행됩니다.
PUT 작업 중 MinIO가 버전 불일치를 감지하면 Bit rot healing이 트리거될 수 있습니다. 객체가 Bit Rot에 의해 손상된 경우, 해당 객체에 대한 패리티 조각이 충분히 존재하면 MinIO는 자동으로 복구를 수행할 수 있습니다.
MinIO scanner를 수행할 수 있지만, 보통은 자동으로 이뤄지는 Bit rot healing 만으로 충분하다고 합니다.
마치며
여기까지 오브젝트 스토리지에 대한 이해와 MinIO의 주요 개념과 동작 방식을 살펴봤습니다.
이제 다음 포스트에서는 실습을 통해서 MinIO를 살펴보겠습니다.
'MinIO' 카테고리의 다른 글
| [4] MinIO - MNMD 배포 (0) | 2025.09.24 |
|---|---|
| [3] MinIO - Direct PV (0) | 2025.09.20 |
| [2] MinIO 사용해보기 (0) | 2025.09.12 |


